
来源:ICCV 2021
贡献:
- 提出基于Swin Transformer的图像修复模型:SwinIR
- 通过大量实验表明SwinIR在SR、denoising、JPEG block removal上都是sota
1. 背景
1-1 图像修复
- 从一个劣质图片修复成一个干净的图片,如:超分、降噪、JPEG压缩区块失真


2. 相关工作
2.1 NLP(Neural Language Processing)
可以看成一个翻译任务(Seq2Seq)
翻译的难点:一词多义 ->根据上下文的信息
常用模型:RNN、LSTM ->全局信息损失
2.2 Self-Attention
Attention($Q$ ,$K$,$V$) = softmax$(\frac{QK^T}{\sqrt{d_k}})V$
计算一个单词与每一个单词的关系(包括自己)

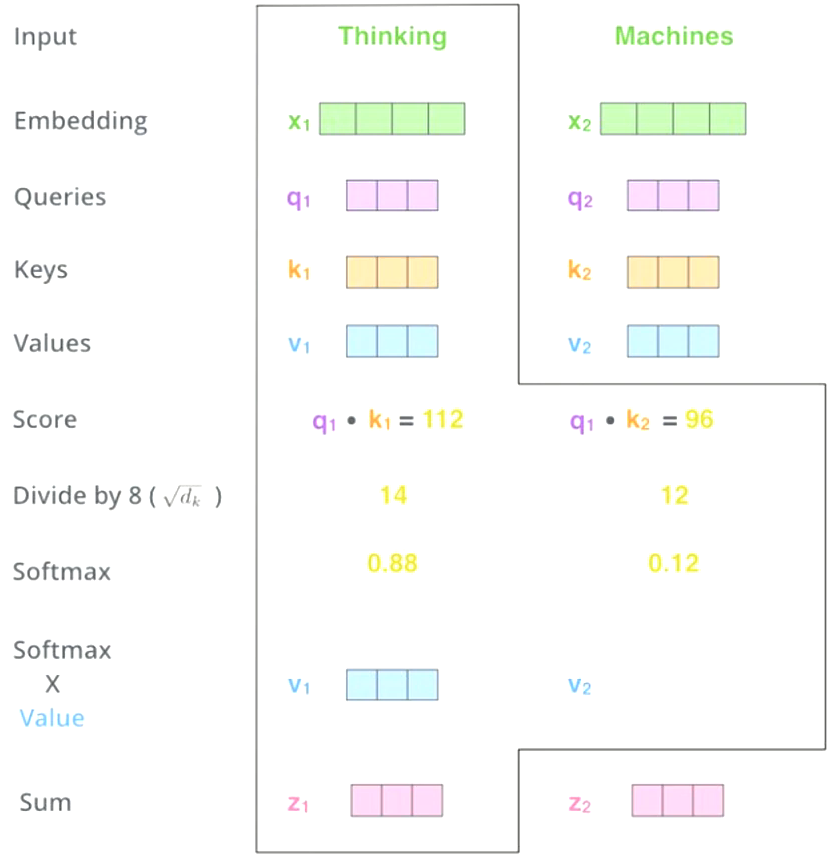
2.3 Multi-head Self-Attention (MSA)
- Ensemble 的self attention,集成多个attention再平均
2.4 Transformer on NLP

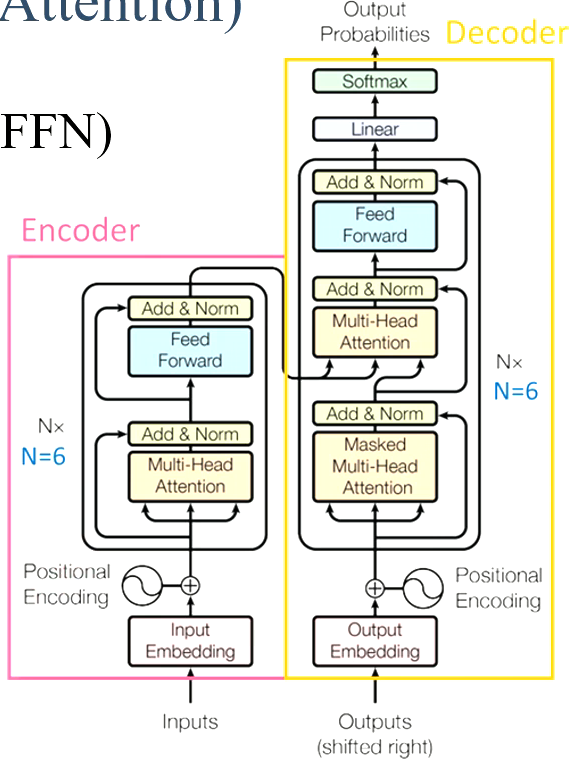
- Transformer在NLP领域效果很好,但是在CV上不太好。
2.5 Transformer on CV
第一篇将Transformer应用到CV的是:ViT
Transformer接收的是一个序列 -> 将图片分割成多个patch

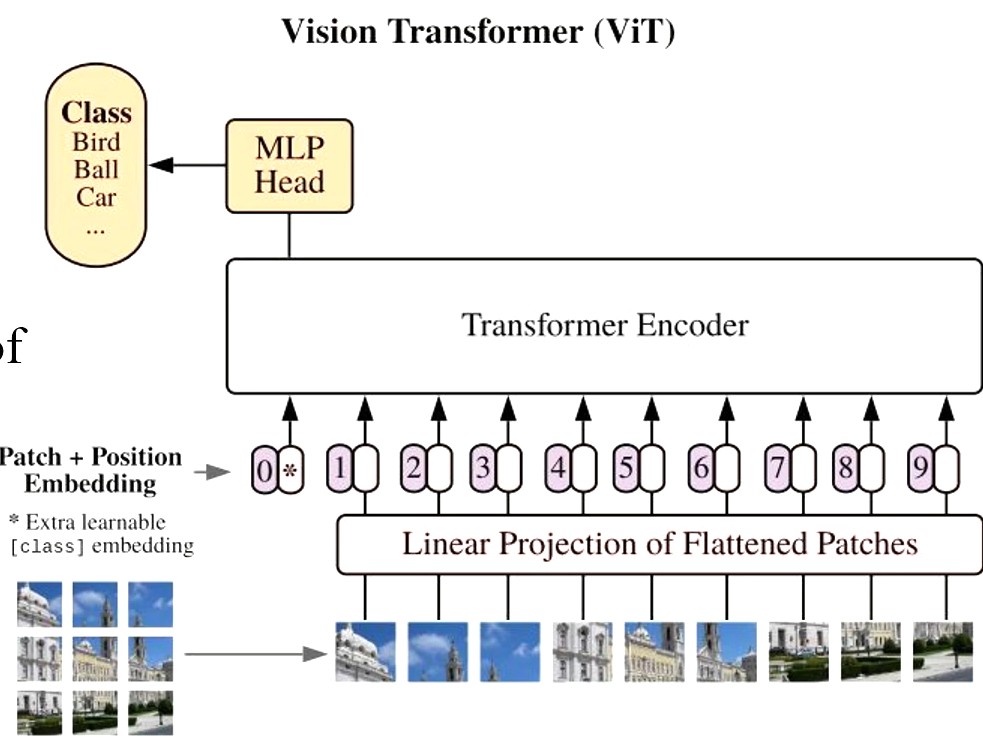
可用于图片分割、图片分类、物体检测
2.6 Swin Transformer
虽然ViT效果还算不错,但是仍然无法超过一些主流的卷积网络,主要原因是Transformer一开始是针对NLP的,NLP是一个一维的问题,图片是高维的问题。
直接分块然后独立地丢入Transformer后会有一个问题:最后得出的结果会有边界的问题(各个分块相交的地方)
Swin Transformer的一个模块包括两个层:

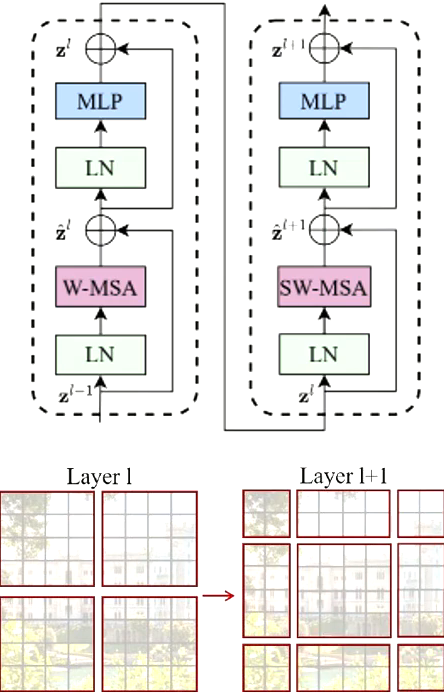
- W-MSA:在原来的小分割patch基础上有一个local的概念,先在local上先做。(可以想象成背景有一个大网格)
- SW-MSA:背景表格不动,将图片往左上或右下做一个shift,这样分割出来的local跟第一层的分割效果就不同了,这样可以解决边界问题。
效果非常好,基本可以取代卷积运算
3 SwinIR
3.1 结构

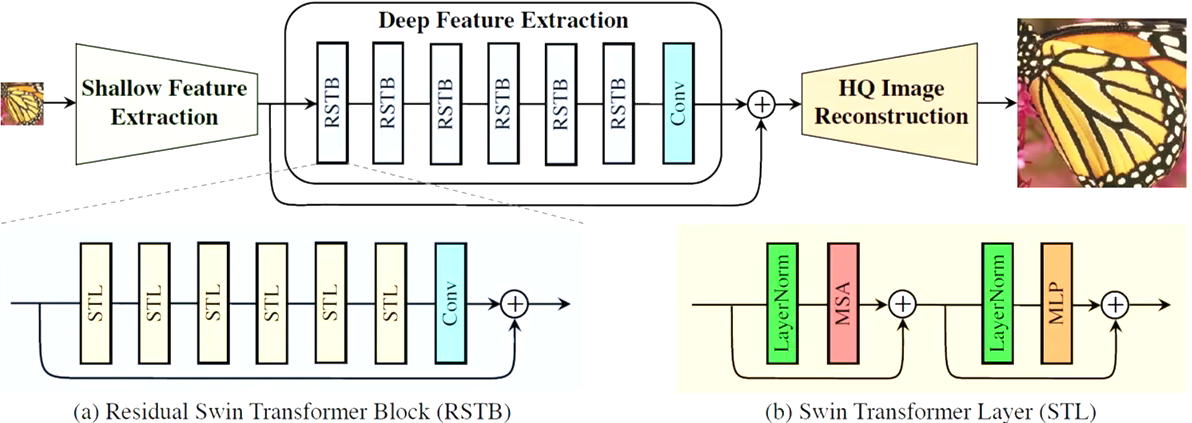
浅层特征提取层 -> 深层特征提取层 -> 重建层
Shallow Feature Extraction:用一个3*3卷积获得低频信息(颜色或者纹理等基础特性)
Deep Feature Extraction:由于Swin Transformer原本使用在高阶的图像处理任务上,这里让他应用到低阶的任务上,效果非常好。
Reconstruction:
- SR:用sub-pixel做up-sample
- Denoising/JPEG:用3*3卷积
Loss function:
- SR:L1 loss -> $l = || I_{RHQ}-I_{HQ}||_1$
- Denoising & JPEG:Charbonnier loss -> $l=\sqrt{||I_{PHQ}-I_{HQ}||^2 + \epsilon^2}$
4. 实验
4.1 Ablation Studies

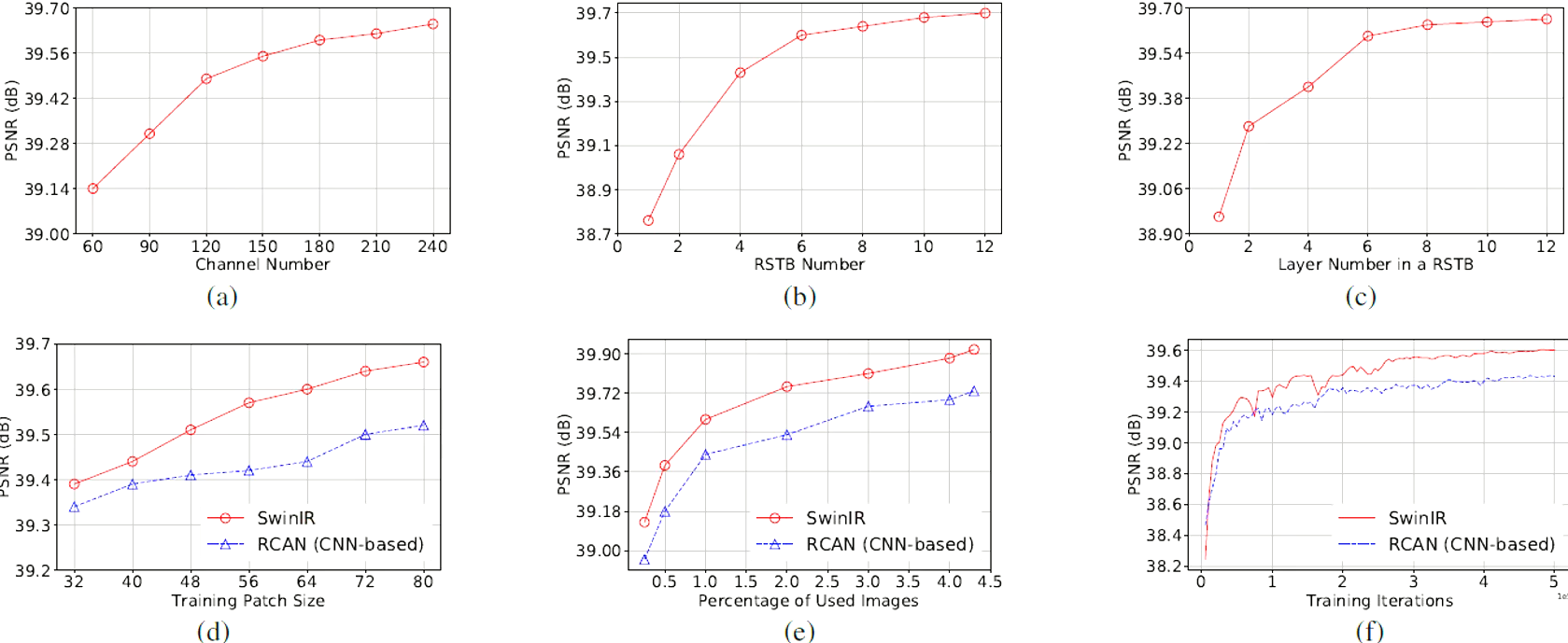
Super Resolution
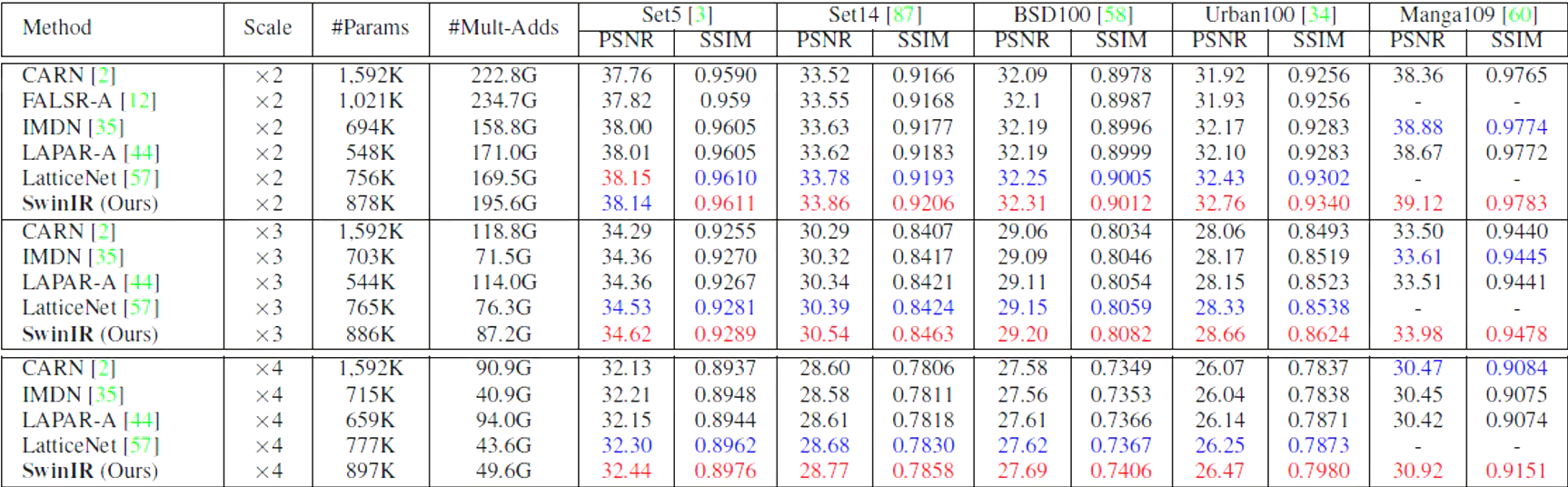
Classical SR


Lightweight image SR(轻量的网络架构)

Real-world image SR


JPEG block removal


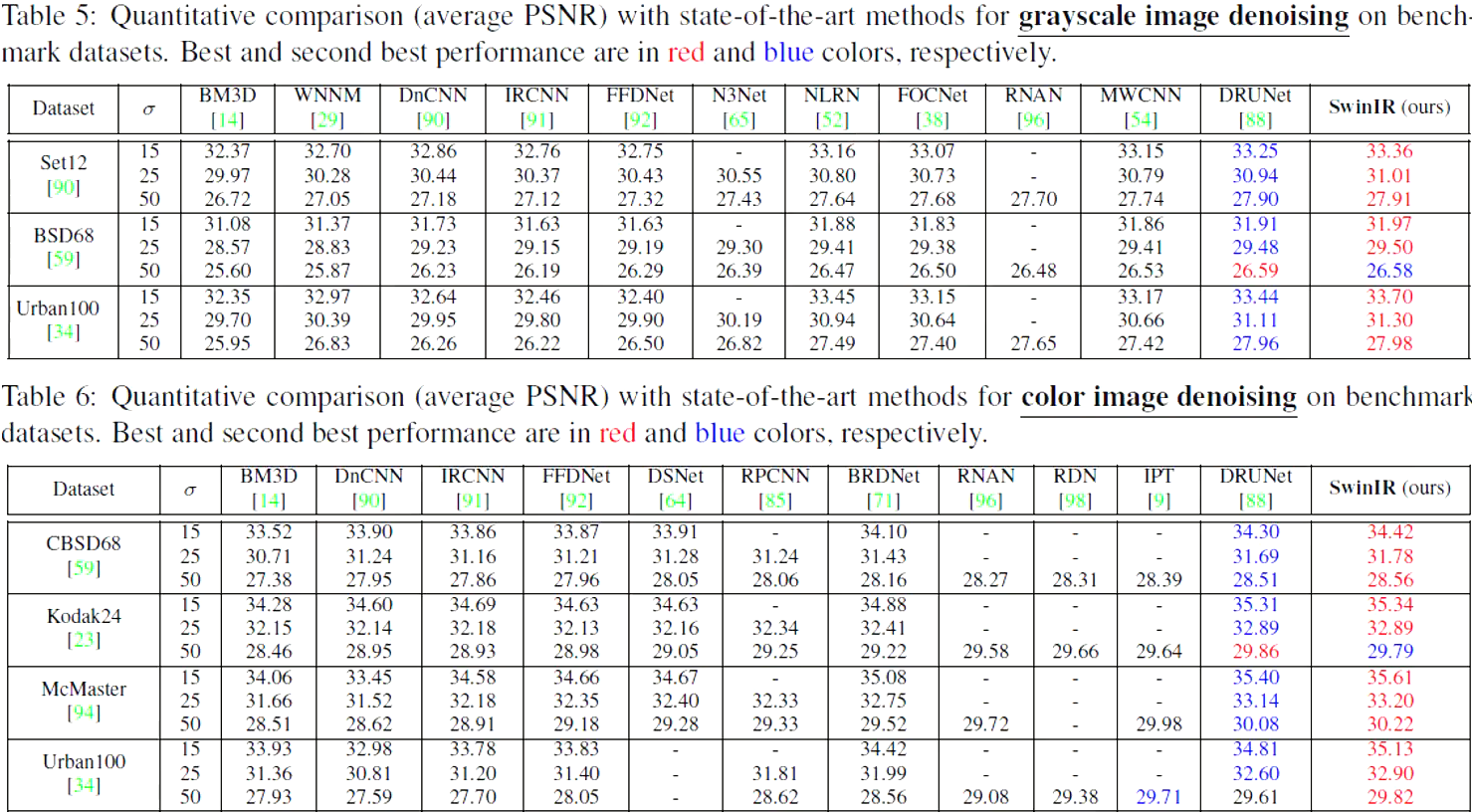
Denoising
Grayscale image denoising
Color image denoising



5 结论
- 提出基于Swin Transformer的图像修复模型:SwinIR
- 通过大量实验表明SwinIR在SR、denoising、JPEG block removal上都是sota