
6 暂退法
模型简单性:
- 维度小
- 参数泛化
- 平滑性
平滑性:函数不应该对其输入的微小变化敏感。例如,当我们对图像进行分类时,我们预计向像素添加一些随机噪声应该是基本无影响的。具有输入噪声的训练等价于Tikhonov正则化。基于此,提出暂退法:在计算后续层之前向网络的每一层注入噪声。因为当训练一个有多层的深层网络时,注入噪声只会在输入‐输出映射上增强平滑性。从表面上看是在训练过程中丢弃(dropout)一些神经元。
需要说明的是,暂退法的原始论文提到了一个关于有性繁殖的类比:神经网络过拟合与每一层都依赖于前一层激活值相关,称这种情况为“共适应性”。作者认为,暂退法会破坏共适应性,就像有性生殖会破坏共适应的基因一样。???
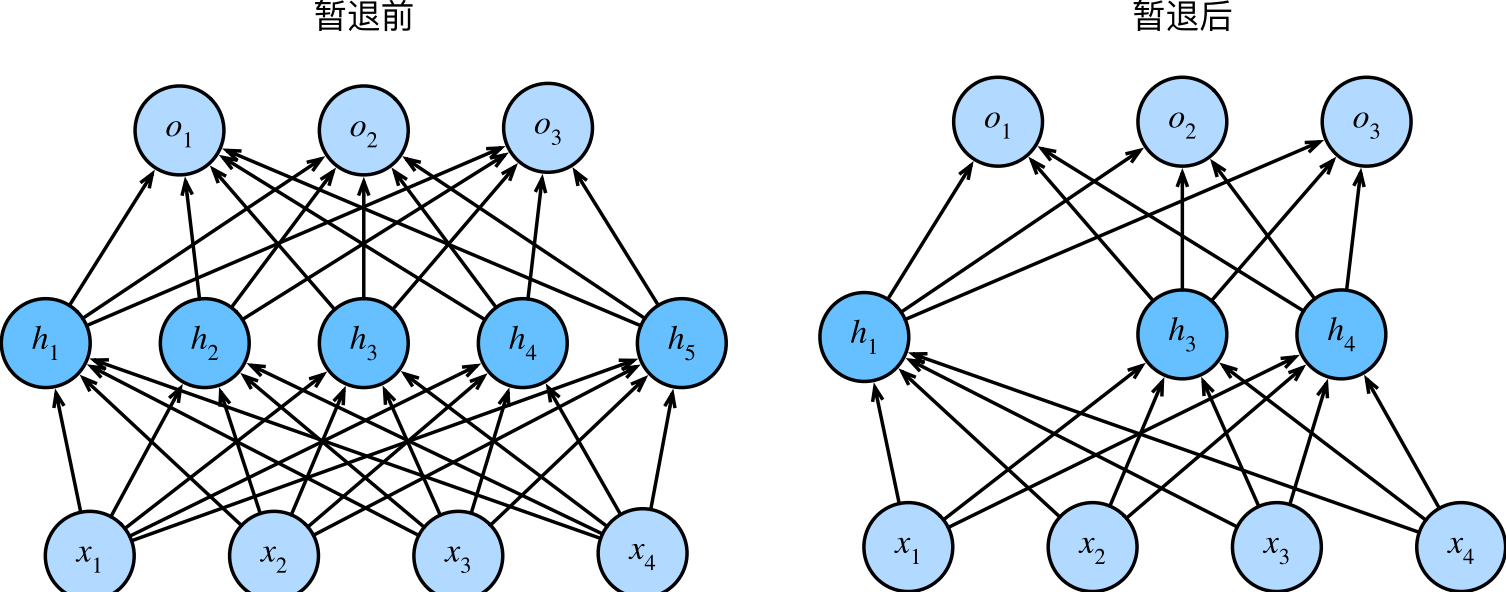
做法:
$h ^\prime =\begin{cases}0 &p \\\\ \frac{h}{1-p} &1-p \\\\ \end{cases}.$这样,输出层的计算不能过度依赖于h1, . . . , h5的任何一个元素。通常,我们在测试时不用暂退法。(一些研究人员在测试时使用暂退法,用于估计神经网络预测的“不确定性”:如果通过许多不同的暂退法遮盖后得到的预测结果都是一致的,那么我们可以说网络发挥更稳定。)

6.1 代码实现
- 1)从U[0,1]抽样
- 2)保留大于p的点/(1-p)
1 | import os |
tensor([[ 0., 1., 2., 3., 4., 5., 6., 7.],
[ 8., 9., 10., 11., 12., 13., 14., 15.]])
tensor([[ 0., 1., 2., 3., 4., 5., 6., 7.],
[ 8., 9., 10., 11., 12., 13., 14., 15.]])
tensor([[ 0., 2., 0., 6., 0., 10., 12., 0.],
[16., 0., 0., 22., 24., 0., 0., 0.]])
tensor([[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.]])
6.1.1 dropout应用到模型
- 将暂退法应用于每个隐藏层的输出(在激活函数之后),并且可以为每一层分别设置暂退概率:常见的技巧是在靠近输入层的地方设置较低的暂退概率。
1 | #1 参数 |


6.1.2 简洁实现
1 | net= nn.Sequential( |

