
7 前向传播、反向传播和计算图
- 以带dropout的单层隐藏层mlp为例
7.1 前向传播
- 按顺序(从输入层到输出层)计算和存储神经网络中每层的结果s。
- 1)输入是$\mathbf{x} \in \mathbb{R}^d$,隐藏层不含偏置,得到中间变量:
$$\mathbf{z}=\mathbf{W}^{(1)}\mathbf{x}$$ - 2)激活:
$$\mathbf{h}=\phi(\mathbf{z})$$ - 3)输出:
$$\mathbf{o}=\mathbf{W}^{(2)}\mathbf{h}$$ - 4)损失:
$$L=l(\mathbf{o},y)$$ - 5)正则化项(权重衰减):
$$s=\frac{\lambda}{2}(||\mathbf{W}^{(1)}||^2_F+||\mathbf{W}^{(2)}||^2_F)$$- 其中矩阵的Frobenius范数是将矩阵展平成向量后应用$L_2$范数。
- 6)目标函数:
$$J=L+s$$
- 1)输入是$\mathbf{x} \in \mathbb{R}^d$,隐藏层不含偏置,得到中间变量:
7.2 前向传播计算图
- 7.1的计算图:

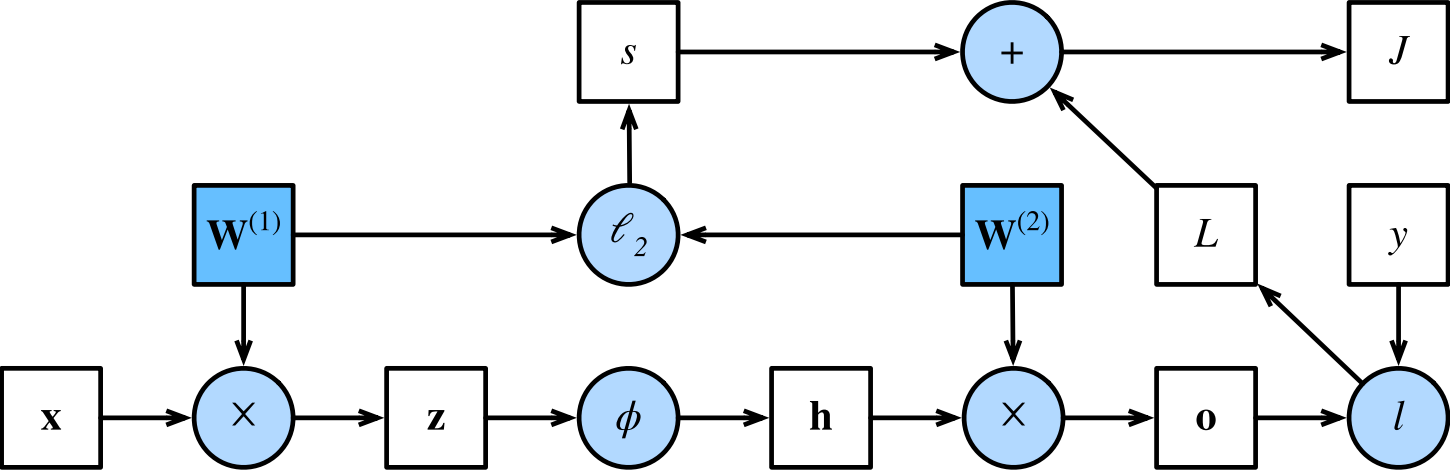
7.3 反向传播
根据微积分中的链式规则,按相反的顺序从输出层到输入层遍历网络。
链式法则:假设有$Y=f(X)$和$Z=g(Y)$,有:
$$\frac{\partial{Z}}{\partial{X}}=prod(\frac{\partial{Z}}{\partial{Y}},\frac{\partial{Y}}{\partial{X}})$$- prod表示一定的操作
针对前向传播计算图计算反向梯度:
$$ \frac{ \partial J}{ \partial L} = 1 \mathrm{ ~ and ~ } \frac{ \partial J}{ \partial s} = 1 $$$$\frac{\partial J}{\partial\mathbf{o}}=\text{prod}\left(\frac{\partial J}{\partial L},\frac{\partial L}{\partial\mathbf{o}}\right)=\frac{\partial L}{\partial\mathbf{o}}\in\mathbb{R}^q$$
$$ \frac{ \partial s}{ \partial \mathbf{W}^ {(1)}}= \lambda \mathbf{W}^ {(1)} \mathrm{~ and ~} \frac{ \partial s}{ \partial \mathbf{W}^ {(2)}}= \lambda \mathbf{W}^ {(2)}$$
$$\frac{\partial J}{\partial\mathbf{W}^{(2)}}=\mathrm{prod}\left(\frac{\partial J}{\partial\mathbf{o}},\frac{\partial\mathbf{o}}{\partial\mathbf{W}^{(2)}}\right)+\mathrm{prod}\left(\frac{\partial J}{\partial s},\frac{\partial s}{\partial\mathbf{W}^{(2)}}\right)=\frac{\partial J}{\partial\mathbf{o}}\mathbf{h}^\top+\lambda\mathbf{W}^{(2)}$$
$$\frac{\partial J}{\partial\mathbf{h}}=\text{prod}\left(\frac{\partial J}{\partial\mathbf{o}},\frac{\partial\mathbf{o}}{\partial\mathbf{h}}\right)=\mathbf{W}^{(2)^\top}\frac{\partial J}{\partial\mathbf{o}}$$
由于激活函数$\phi$是按元素计算的,因此计算$\frac{\partial J}{\partial \mathbf{z}}$需要使用按元素乘法运算符:
$$\frac{\partial J}{\partial\mathbf{z}}=\mathrm{prod}\left(\frac{\partial J}{\partial\mathbf{h}},\frac{\partial\mathbf{h}}{\partial\mathbf{z}}\right)=\frac{\partial J}{\partial\mathbf{h}}\odot\phi^{\prime}\left(\mathbf{z}\right)$$$$\begin{aligned}\frac{\partial J}{\partial\mathbf{W}^{(1)}}&=\text{prod}\left(\frac{\partial J}{\partial\mathbf{z}},\frac{\partial\mathbf{z}}{\partial\mathbf{W}^{(1)}}\right)+\text{prod}\left(\frac{\partial J}{\partial s},\frac{\partial s}{\partial\mathbf{W}^{(1)}}\right)=\frac{\partial J}{\partial\mathbf{z}}\mathbf{x}^\top+\lambda\mathbf{W}^{(1)}\end{aligned}$$
7.4 训练神经网络
- 训练神经网络时,对于前向传播,沿着依赖的方向遍历计算图并计算路径上的所有变量。然后将这些用于反向传播,其中计算顺序与计算图的相反。
- 一方面,在前向传播期间计算正则项取决于模型参数W(1)和 W(2)的当前值。它们是由优化算法根据最近迭代的反向传播给出的。
- 另一方面,反向传播期间参数$\frac{\partial J}{\partial W^{(2)}}$的梯度计算,取决于由前向传播给出的隐藏变量h的当前值。
- 因此,在训练神经网络时,在初始化模型参数后,我们交替使用前向传播和反向传播,利用反向传播给出的梯度来更新模型参数。
- 反向传播重复利用前向传播中存储的中间值,以避免重复计算。带来的影响之一是我们需要保留中间值,直到反向传播完成。