
7 Transformer
自注意力同时具有并行计算和最短和最大路径长度这两个优势。
对比之前仍然依赖rnn实现输入表示的自注意力模型,Transformer完全基于注意力机制,没有任何卷积层或rnn层。
7.1 模型
编码器-解码器架构。

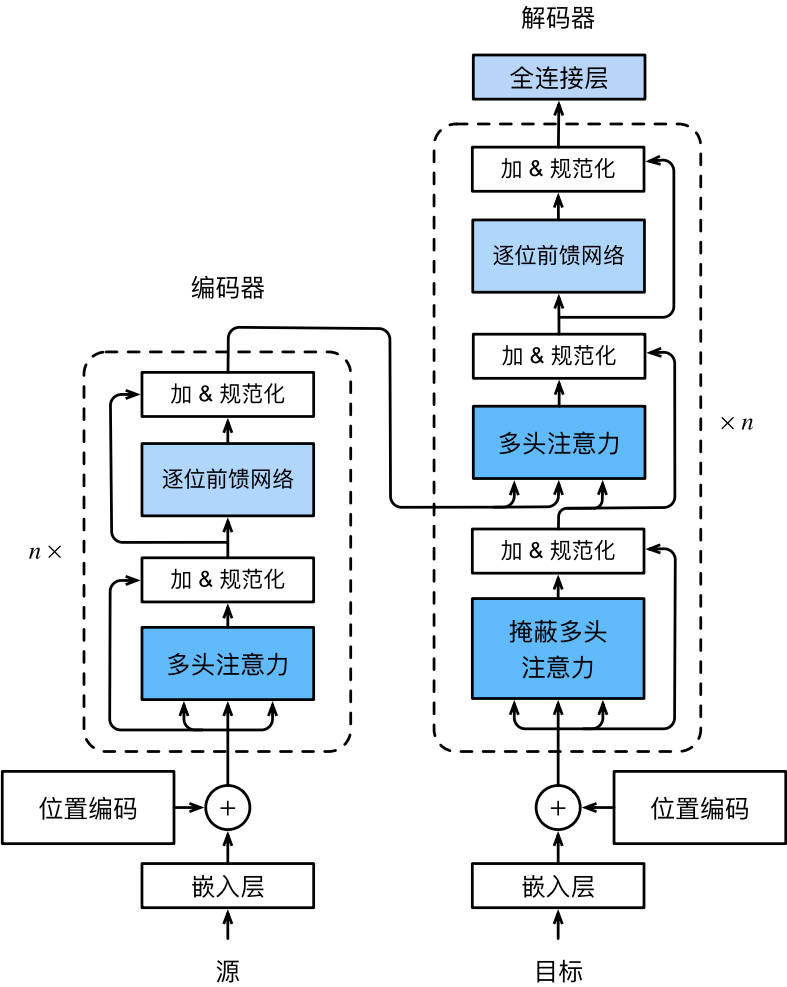
编码器由多个层叠加,每个层有两个子层(sublayer)
- 第一个子层是multi-head self-attention汇聚;
- 第二个子层是基于位置的前馈网络(positionwise feed-forward network)
- 在计算编码器的注意力时,q,k,v都来自前一个编码器层的输出。输入序列对应的每个位置,Transformer编码器都将输出一个d维表示向量
解码器多了一个子层:encoder-decoder attention层。其中q来自前一个解码器层的输出,但k,v来自整个编码器的输出。
在解码器注意力中,q,k,v都来自撒谎给你一个解码器层的输出。但是解码器中的每一个位置只能考虑该位置之前的所有位置。这种masked attention保留了自回归(auto-regressive)属性,确保预测仅依赖于已生成的输出词元。
1 | import math |
7.2 基于位置的前馈网络
- 基于位置的前馈网络对序列中所有位置的表示进行变换时 使用的是同一个mlp,因此称前馈网络是基于位置的。
- (batch, n, hidden) -> (batch, n, output)
1 | #@save |
- 因为使用同一个多层感知机对所有位置上的输入进行变换,所以当这些位置的输入相同时,输出相同:
- 输入3个序列,特征长度4;由于输入的三个序列一样,所以输出的三个序列也一样。
1 | ffn = PositionWiseFFN(4,4,8) |
tensor([[-0.1351, 0.5875, 1.0552, -0.2889, -1.1500, -1.1897, -0.7666, 0.4518],
[-0.1351, 0.5875, 1.0552, -0.2889, -1.1500, -1.1897, -0.7666, 0.4518],
[-0.1351, 0.5875, 1.0552, -0.2889, -1.1500, -1.1897, -0.7666, 0.4518]],
grad_fn=<SelectBackward0>)
7.3 残差连接和层规范化
层规范化和批量规范化目标相同
- 层规范化:基于特征维度进行规范化
尽管批量规范化在cv中广泛应用,但nlp中(输入通常是变长序列)层规范化更好。
对比不同维度的层规范化和批量规范化的效果:(一个横着归一化,一个竖着归一化)
1 | ln = nn.LayerNorm(2) |
layer norm: tensor([[-1.0000, 1.0000],
[-1.0000, 1.0000]], grad_fn=<NativeLayerNormBackward0>)
batch norm: tensor([[-1.0000, -1.0000],
[ 1.0000, 1.0000]], grad_fn=<NativeBatchNormBackward0>)
- 使用残差连接和层规范化:
1 | #@save |
torch.Size([2, 3, 4])
7.4 编码器
1 | #@save |
- Transformer编码器不会改变输入的形状
1 | X = torch.ones((2, 100, 24)) |
torch.Size([2, 100, 24])
Transformer编码器:堆叠了多个EncoderBlock
- 由于使用的[-1,1]的固定位置编码,因此通过学习得到的input的嵌入表示需要先乘以embedding dim的平方根进行重新缩放,然后与位置编码相加???
1 | #@save |
- 创建一个两层的Transformer编码器,输出形状(批大小,时间步数目,num_hiddens)。
1 | encoder = TransformerEncoder(200, 24, 24, 24, 24, [100, 24], 24, 48, 8, 2, 0.5) |
torch.Size([2, 100, 24])
7.5 解码器
三个子层:
解码器self attention
编码器-解码器attention
基于位置的前馈网络
seq to seq模型中,在训练阶段,其输出序列的所有位置(时间步)的词元都是已知的;然而在预测阶段,其输出序列的词元是逐个生成的。因此,在任何解码器时间步中,只有生成的词元才能用于解码器的self attention计算中。为了在解码器中保留自回归属性,其掩蔽自注意力设定了参数dec_valid_lens,以便任何查询都只会与解码器中所有已经生成词元的位置进行注意力计算。
1 | class DecoderBlock(nn.Module): |
- 为了便于在encoder-decoder attention中进行缩放点积计算和残差连接中进行加法计算,encoder和decoder的特征维度都是num hiddens
1 | decoder_blk = DecoderBlock(24,24,24,24,[100,24],24,48,8,0.5,0) |
torch.Size([2, 100, 24])
- Transformer解码器
1 | class TransformerDecoder(d2l.AttentionDecoder): |
7.6 训练
1 | num_hiddens, num_layers, dropout, batch_size, num_steps = 32, 2, 0.1, 64, 10 |
loss 0.031, 7034.3 tokens/sec on cpu
![]()
- 测试翻译,计算BLEU分数
1 | engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .'] |
go . => va !, bleu 1.000
i lost . => j'ai perdu ., bleu 1.000
he's calm . => il est calme ., bleu 1.000
i'm home . => je suis chez moi ., bleu 1.000
- 可视化Transformer的注意力权重,编码器自注意力权重为(编码器层数,注意力头数,num_steps或查询的数目,num_steps或键值对的数目)
1 | enc_attention_weights = torch.cat(net.encoder.attention_weights, 0).reshape((num_layers,num_heads,-1,num_steps)) |
2
torch.Size([4, 10, 10])
torch.Size([2, 4, 10, 10])
在编码器self attention中,q,k都来自相同的输入序列。因为填充词元是不携带信息的,因此通过指定输入序列的有效长度可以避免q与使用填充词元的位置计算注意力。
逐行呈现两层4头注意力的权重。每个注意力头根据q,k,v的不同表示子空间来表示不同的注意力。
1 | d2l.show_heatmaps(enc_attention_weights.cpu(), xlabel='Key positions',ylabel='Query positions', titles=['Head %d' % i for i in range(1, 5)],figsize=(7, 3.5)) |
![]()
- 为了可视化解码器注意力权重,需要完成更多数据操作工作。如用0填充被掩蔽的注意力权重。值得注意的是,解码器的注意力权重和encoder-decoder注意力权重都有相同的查询:即以序列开始词元(BOS)开头,再与后续输出的词元共同组成序列。
1 | dec_attention_weights_2d = [ |
(torch.Size([2, 4, 6, 10]), torch.Size([2, 4, 6, 10]))
- 由于解码器自注意力的自回归属性,查询不会对当前位置之后的“键-值”对进行注意力计算。
1 | # Plusonetoincludethebeginning-of-sequencetoken |
![]()
- 与编码器的自注意力的情况类似,通过指定输入序列的有效长度,输出序列的查询不会与输入序列中填充位置的词元进行注意力计算。
1 | d2l.show_heatmaps(dec_inter_attention_weights, xlabel='Key positions',ylabel='Query positions', titles=['Head %d' % i for i in range(1, 5)],figsize=(7, 3.5)) |
![]()