
5 多GPU训练
- 分割数据到多个设备上,并使其能够正常工作呢
5.1 问题拆分
对于需要分类的小批量训练数据,我们有以下选择
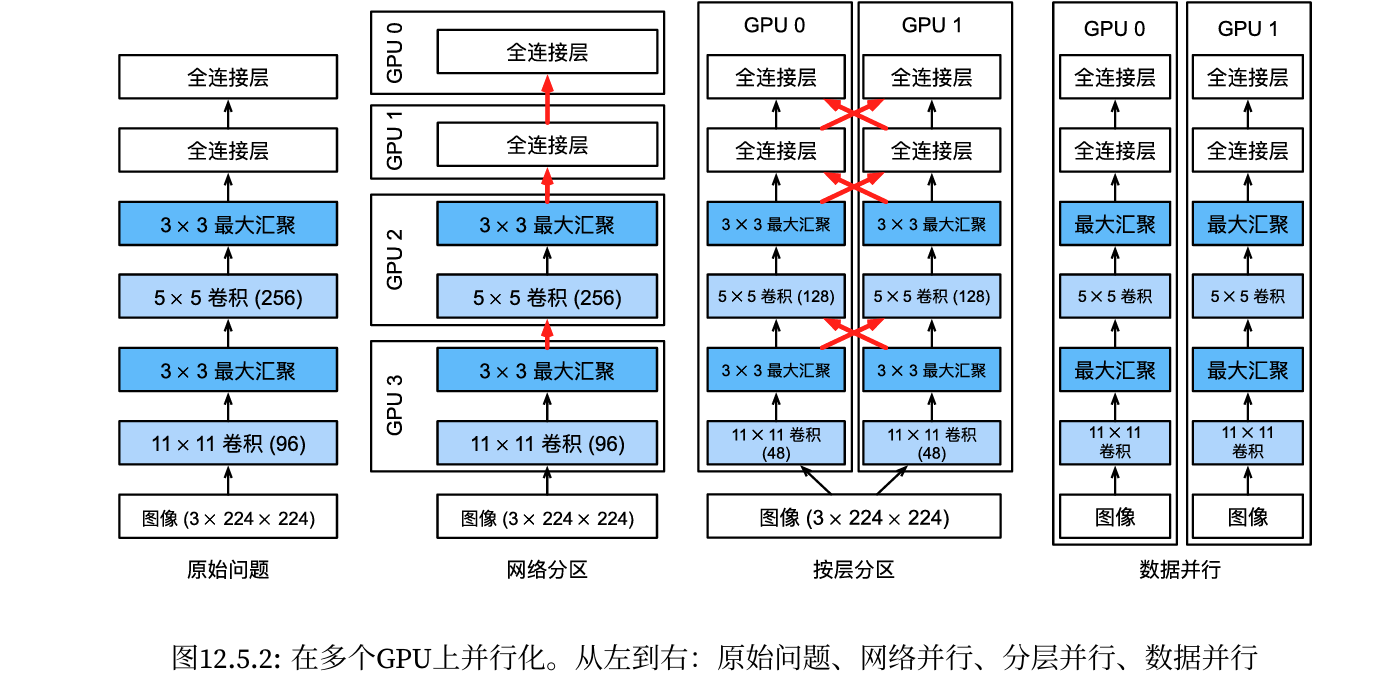
第一种方法,在多个GPU之间拆分网络。也就是说,每个GPU将流入特定层的数据作为输入,跨多个后续层对数据进行处理,然后将数据发送到下一个GPU。与单个GPU所能处理的数据相比,我们可以用更大的网络处理数据。此外,每个GPU占用的显存(memoryfootprint)可以得到很好的控制,虽然它只是整个网络显存的一小部分。
- 然而,GPU的接口之间需要的密集同步可能是很难办的,特别是层之间计算的工作负载不能正确匹配的时候,还有层之间的接口需要大量的数据传输的时候(例如:激活值和梯度,数据量可能会超出GPU总线的带宽)此外,计算密集型操作的顺序对拆分来说也是非常重要的,其本质仍然是一个困难的问题,目前还不清楚研究是否能在特定问题上实现良好的线性缩放。综上所述,除非存框架或操作系统本身支持将多个GPU连接在一起,否则不建议这种方法。
第二种方法,拆分层内的工作。例如,将问题分散到4个GPU,每个GPU生成16个通道的数据,而不是在单个GPU上计算64个通道。对于全连接的层,同样可以拆分输出单元的数量。如下图, 其策略用于处理显存非常小(当时为2GB)的GPU。当通道或单元的数量不太小时,使计算性能有良好的提升。此外,由于可用的显存呈线性扩展,多个GPU能够处理不断变大的网络。


- 然而,我们需要大量的同步或屏障操作(barrieroperation),因为每一层都依赖于所有其他层的结果。此外,需要传输的数据量也可能比跨GPU拆分层时还要大。因此,基于带宽的成本和复杂性,我们同样不推荐这种方法。- 最后一种方法,跨多个GPU对数据进行拆分。这种方式下,所有GPU尽管有不同的观测结果,但是执行着相同类型的工作。在完成每个小批量数据的训练之后,梯度在GPU上聚合。这种方法最简单,并可以应用于任何情况,同步只需要在每个小批量数据处理之后进行。也就是说,当其他梯度参数仍在计算时,完成计算的梯度参数就可以开始交换。而且,GPU的数量越多,小批量包含的数据量就越大,从而就能提高训练效率。但是,添加更多的GPU并不能让我们训练更大的模型。

5.2 数据并行
- 假设一台机器有k个GPU。给定需要训练的模型,虽然每个GPU上的参数值都是相同且同步的,但是每个GPU都将独立地维护一组完整的模型参数。例如,图演示了在k=2时基于数据并行方法训练模型。


一般来说,k个GPU并行训练过程如下:
在任何一次训练迭代中,给定的随机的小批量样本都将被分成k个部分,并均匀地分配到GPU上;
每个GPU根据分配给它的小批量子集,计算模型参数的损失和梯度;
将k个GPU中的局部梯度聚合,以获得当前小批量的随机梯度;
聚合梯度被重新分发到每个GPU中;
每个GPU使用这个小批量随机梯度,来更新它所维护的完整的模型参数集。
当在k个GPU上训练时,小批量的大小为k的倍数,这样每个GPU都有相同的工作量,就像只在单个GPU上训练一样。因此,在16‐GPU服务器上可以显著地增加小批量数据量的大小,同时可能还需要相应地提高学习率。还请注意,批量规范化也需要调整,例如,为每个GPU保留单独的批量规范化参数。
5.3 定义网络
1 | %matplotlib inline |
5.4 数据同步
对于高效的多GPU训练,我们需要两个基本操作。首先,我们需要向多个设备分发参数并附加梯度(get_params)如果没有参数,就不可能在GPU上评估网络。
第二,需要跨多个设备对参数求和,也就是说,需要一个allreduce函数。
1 | def get_params(params, device): |
b1 权重: tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
device='cuda:0', requires_grad=True)
b1 梯度: None
由于还没有进行任何计算,因此权重参数的梯度仍然为零。
假设现在有一个向量分布在多个GPU上,下面的allreduce函数将所有向量相加,并将结果广播给所有GPU。请注意,我们需要将数据复制到累积结果的设备,才能使函数正常工作。
1 | def allreduce(data): |
allreduce之前:
tensor([[1., 1.]], device='cuda:0') tensor([[1., 1.]], device='cuda:0')
allreduce之后:
tensor([[2., 2.]], device='cuda:0') tensor([[2., 2.]], device='cuda:0')
5.5 数据分发
- 我们需要一个简单的工具函数,将一个小批量数据均匀地分布在多个GPU上。例如,有两个GPU时,我们希望每个GPU可以复制一半的数据。因为深度学习框架的内置函数编写代码更方便、更简洁,所以在4×5矩阵上使用它进行尝试。
1 | data = torch.arange(20).reshape(4, 5) |
input : tensor([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19]])
load into [device(type='cuda', index=0), device(type='cuda', index=0)]
output: (tensor([[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]], device='cuda:0'), tensor([[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19]], device='cuda:0'))
5.6 训练
1 | def train_batch(X, y, device_params, devices, lr): |