DDIM Inversion
- 给定一张无噪声的图片和一个训练好的denoiser,找到一个初始噪声(这个噪声通过去噪可以得到无噪声图片)(红线)


- 这个过程与diffusion的forward前向加噪过程有点像
- forward过程不断sample一个noise再加上
- inversion过程中不是加的随机noise,而是通过denoiser推断出来的固定的噪声
CLIP
Latent Diffusion
- 通过一个encoder从pixel space压缩到latent space
微调
1)LoRA
- 个性化生成模型,比如用户想生成动漫风格图片,原始SD没有见过这种concept
- 模型定制化,微调,训练参数少

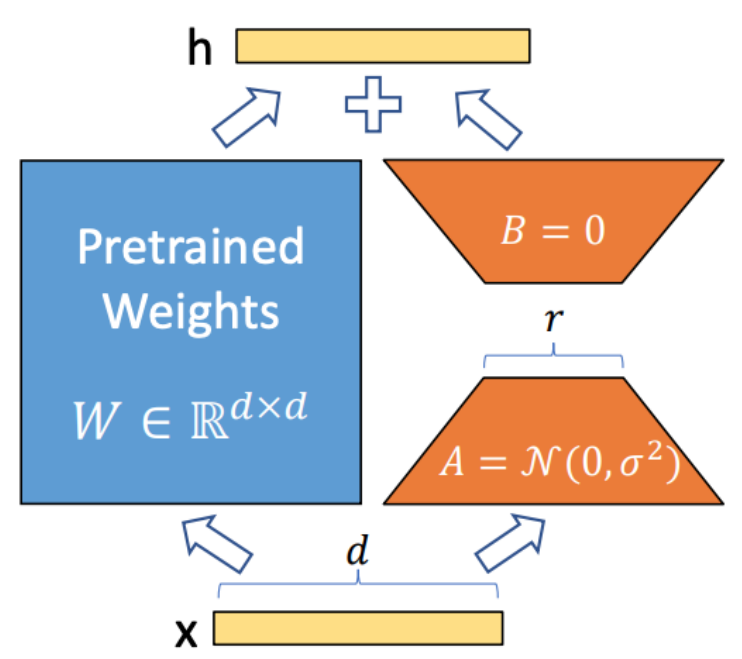
- train右边的,将原始输出和新的输出结合
2)DreamBooth


- 对某个具体的概念(比如红色的书包)给几张图,能够通过训练把这个概念学到网络里面,然后就能生成不同场景下的红色书包。

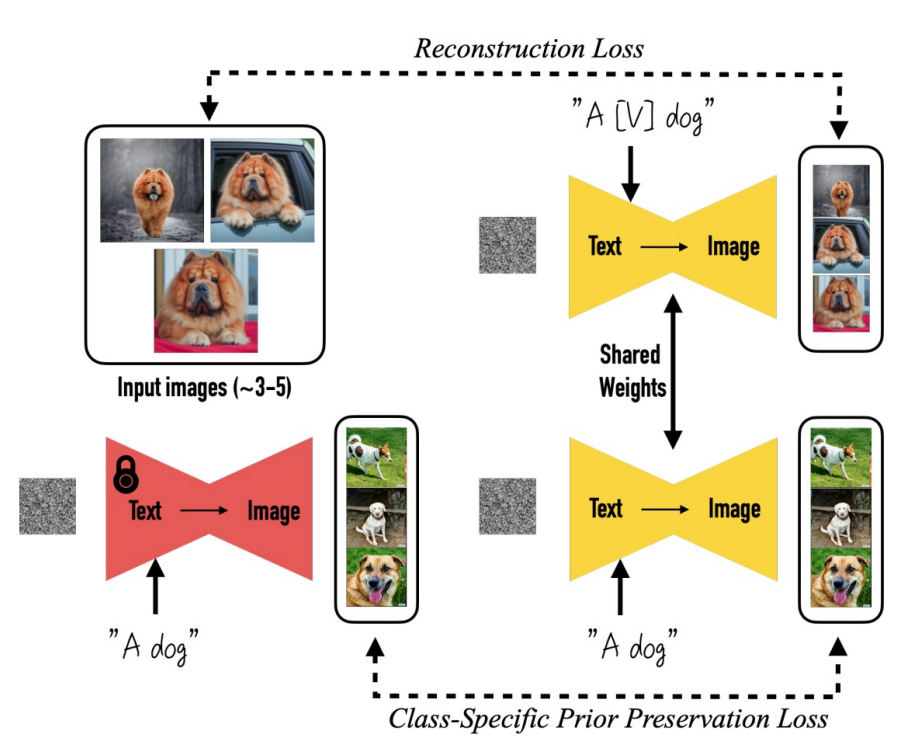
有一个文本token( [v] )来对应这个concept,然后用这几张图片来重新调整diffusion的权重。
当条件中输入了这种特定的token,网络就会被激活,去生成包含这种特定概念的图片
3)ControlNet


- 给一些更好的,细粒度的前置条件,比如Canny edge或human pose

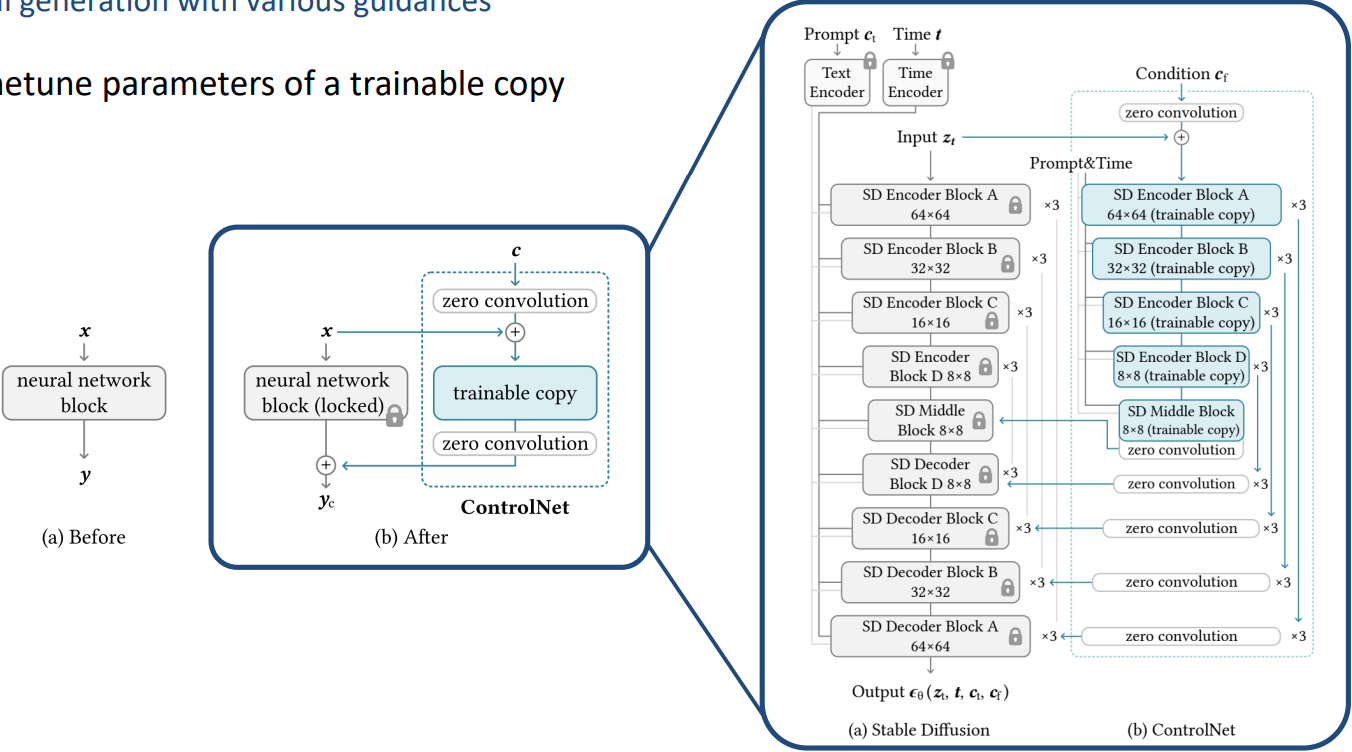
- 跟lora有点像,左边原始权重不动,右边把原始权重复制一份,只训练复制部分,复制的部分有其他的condition作为输入,比如edge或pose图。
- 通过这种方式可以把新的condition融入
2. 视频生成
2.0 问题定义
- 视频生成就是将原本文生图中2D的output变成3D
1)3D Conv
- 一个比较早的比较经典的工作:3D convolution

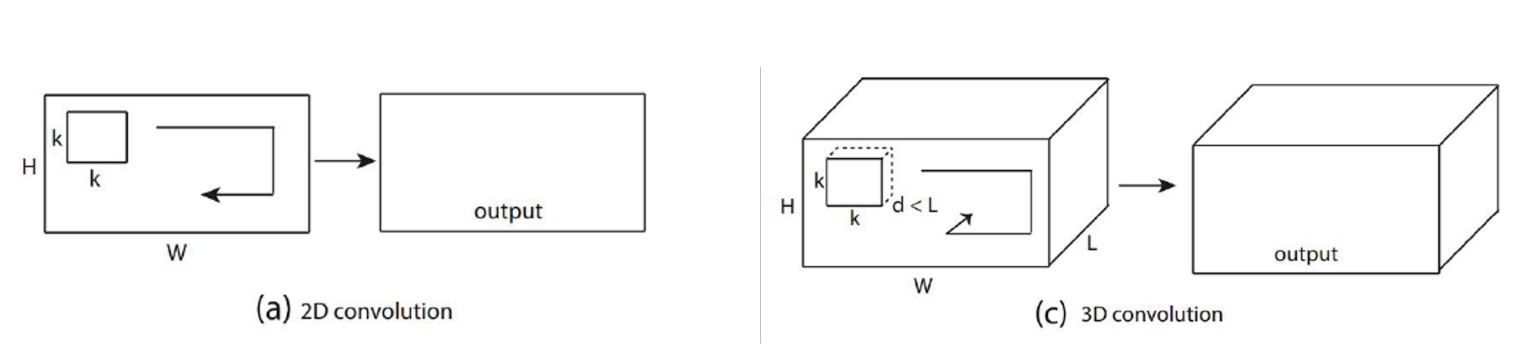
- 2D卷积
- 给一张图片,然后用一个2D的kernel在图片上slide over,然后生成output图片
- 3D卷积
- 输入是3D,kernel也是3D,时间维度上也会进行slide
2)(2+1)D Conv

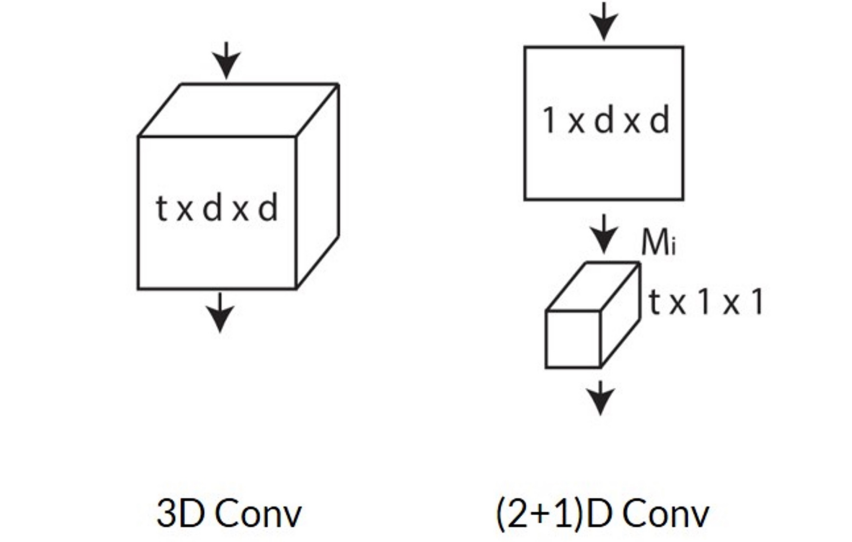
- 3D卷积计算开销大
- 可以先在spacial上做卷积,然后在temporal上做卷积
2.1 早期工作
2.1.1 VDM

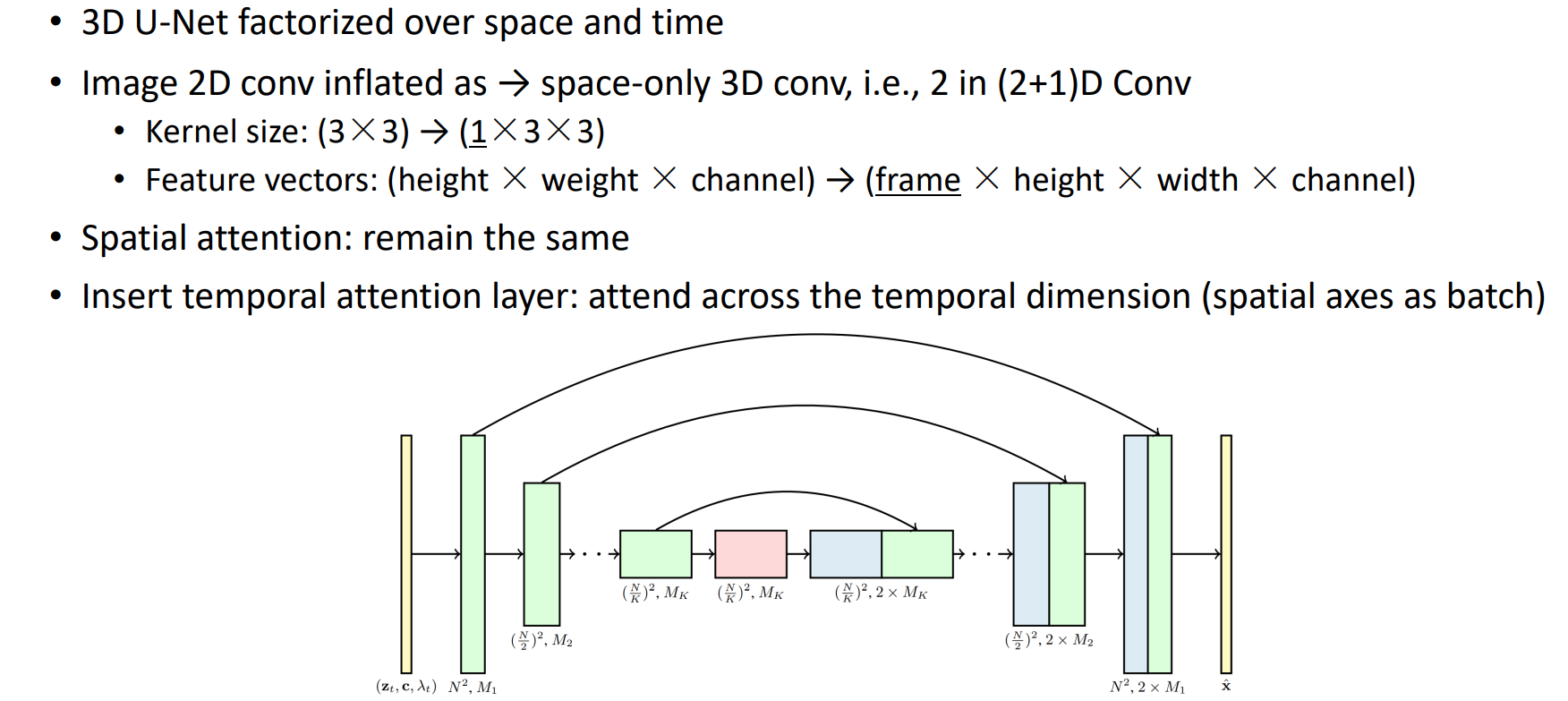
用(2+1)D的形式将时间空间分开的Unet
把Unet中2D的卷积变成3D(只是空间上的3D),将kernel size从(3*3)变成(1*3*3)。在temporal上没有做任何操作,
加了一个temporal attention layer,相当于把spatial层面的信息都当作batch层面,只在temporal层面做attention
2.1.2 Make-A-Video

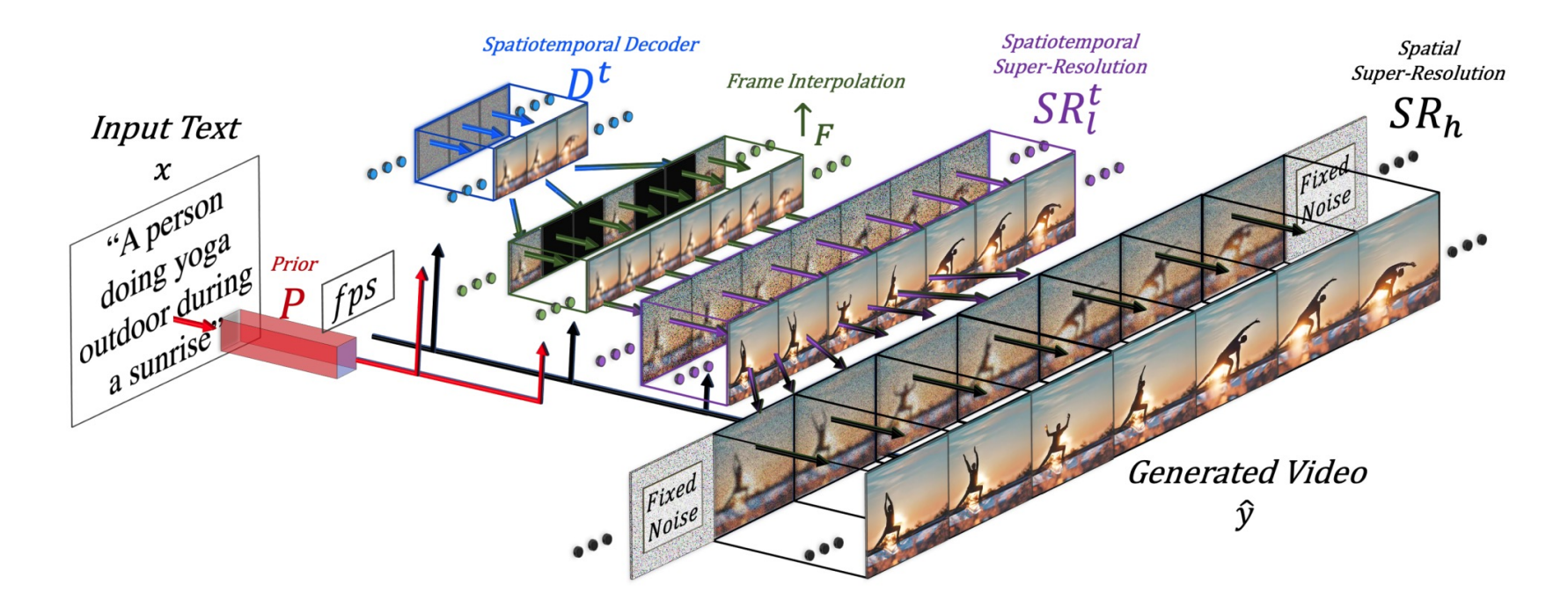


多级生成的框架
Spatiotemporal Decoder从原始noise大概recover出来一些关键帧,包括比较小的时候他长什么样子,看看时空上长什么样。
Frame Interpolation插帧
时间空间超分

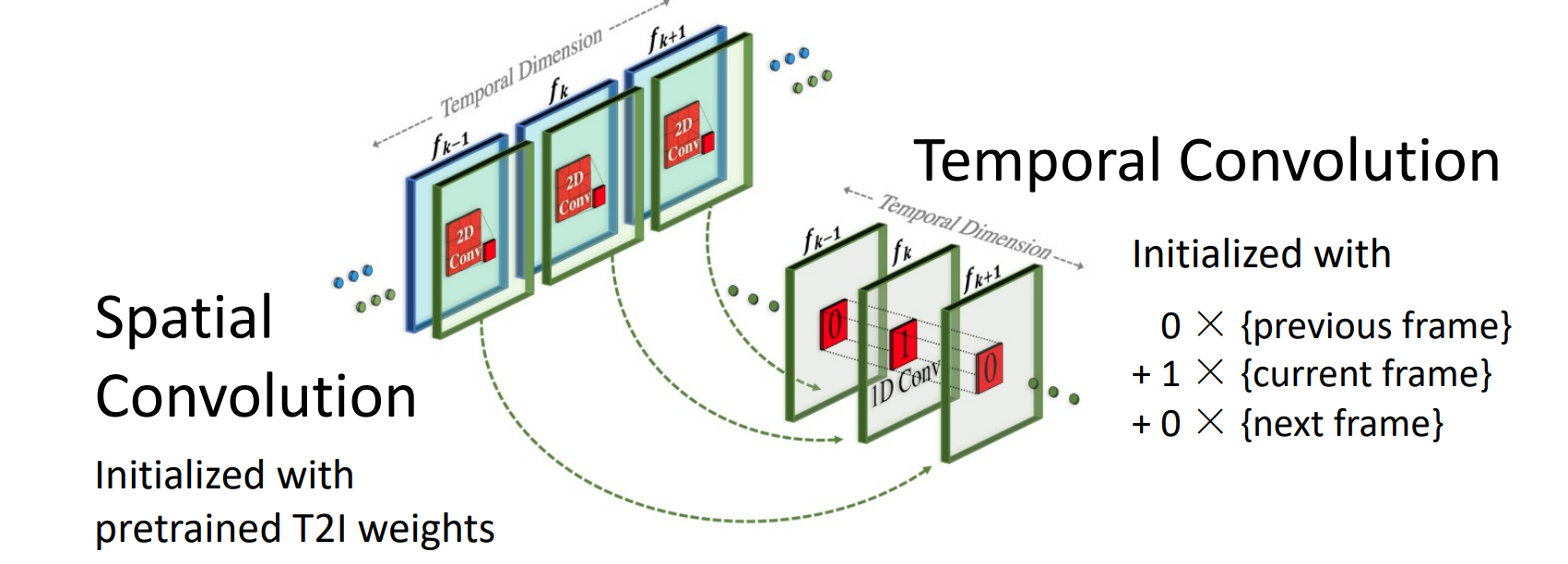
更接近(2+1)D的形式,
先用2D的spatial Convolution(用已经训好的T2I模型进行初始化)
然后用temporal convolution在时间维度上做convolution

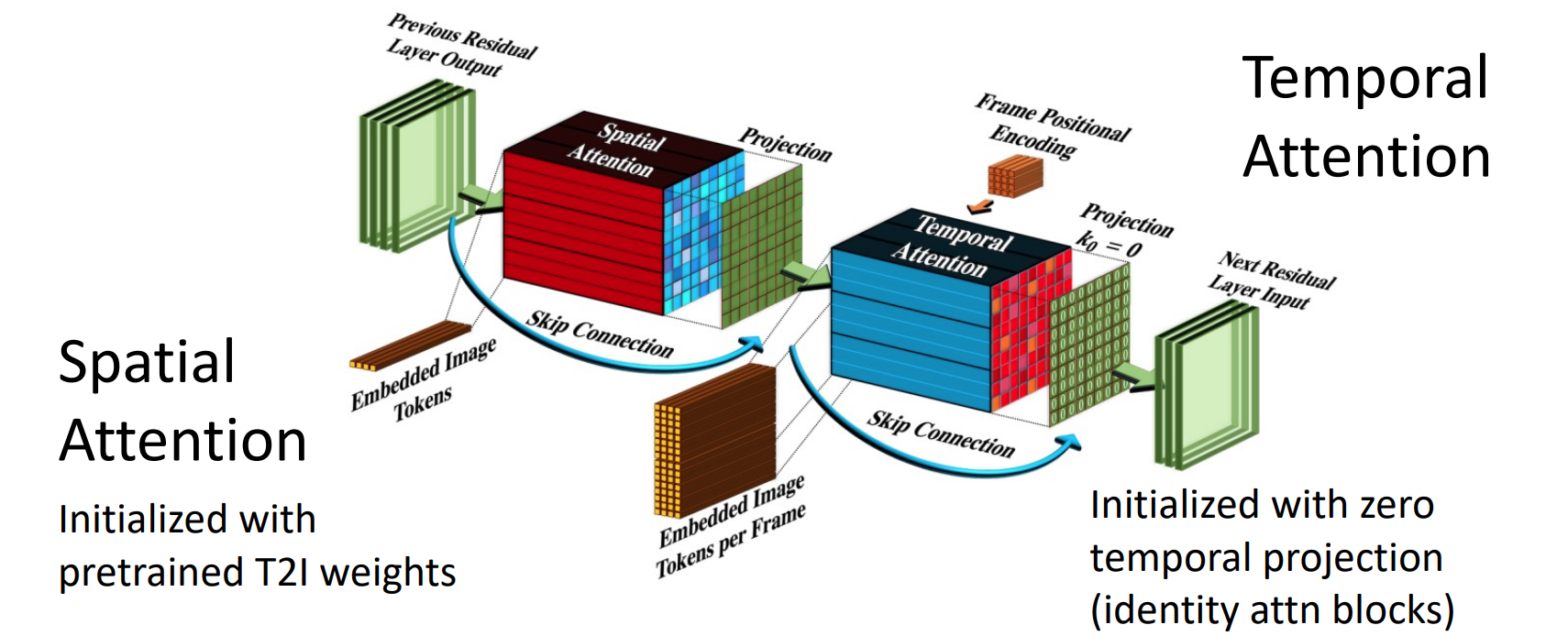
- attention layer也分为spatial atention与temporal attention


评价指标
1)图片层面


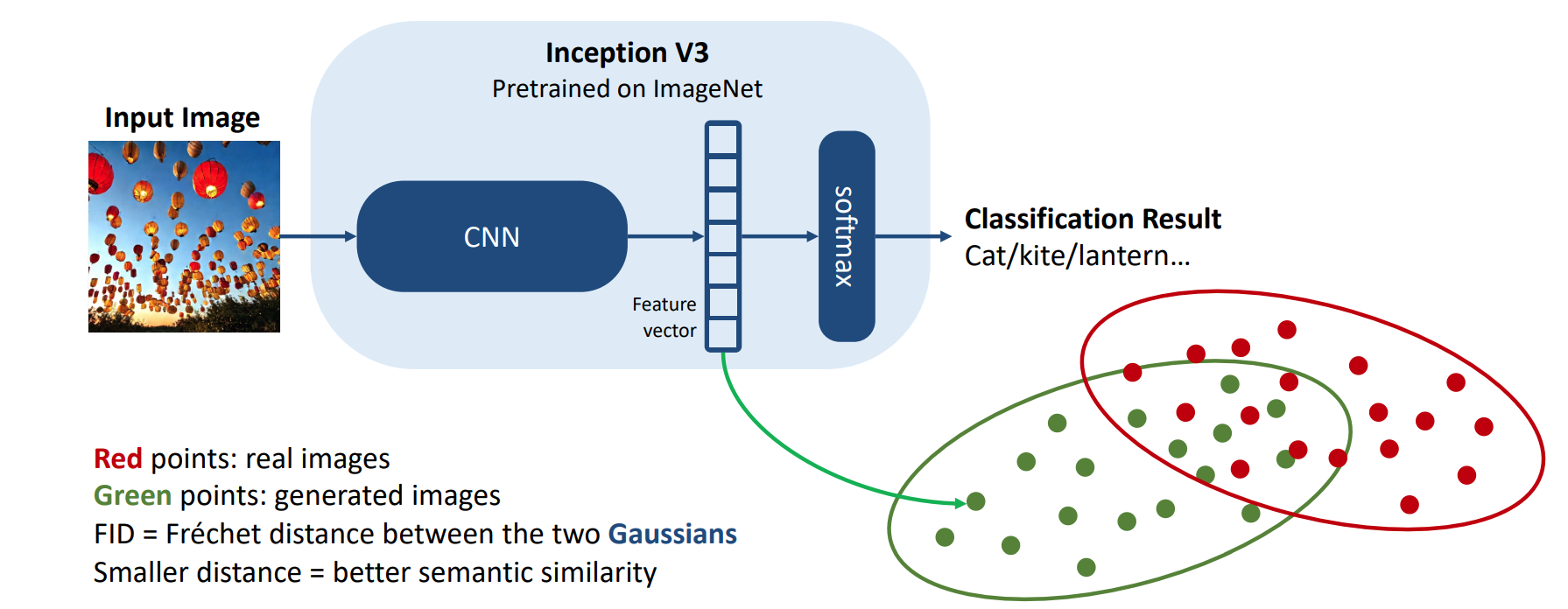
fid评估两个distribution的差距有多大(语义层面的信息,high level)

PSNR(pixel层面,两个图片相减)

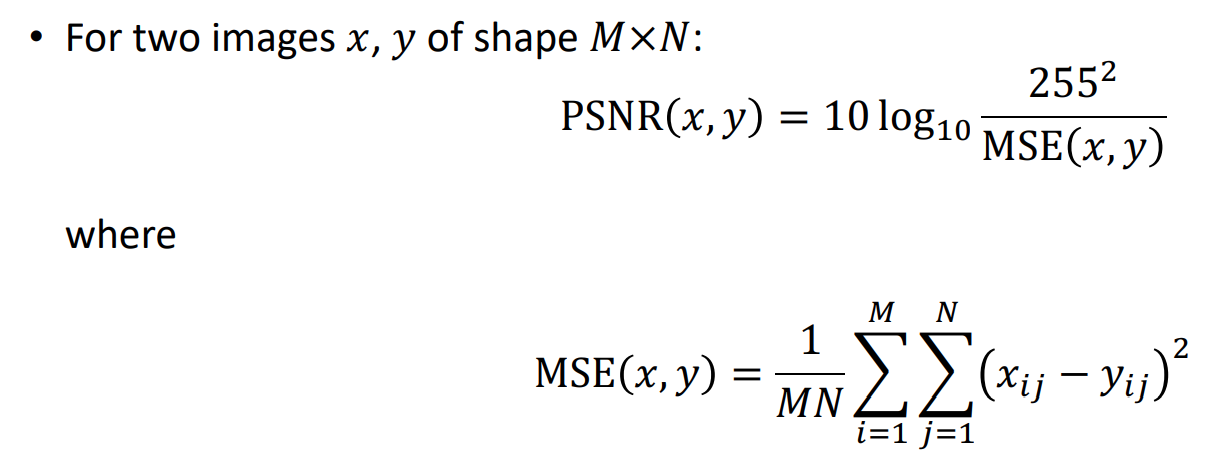
SSIM(pixel层面,更复杂的计算,评价标准)


CLIP Simialarity

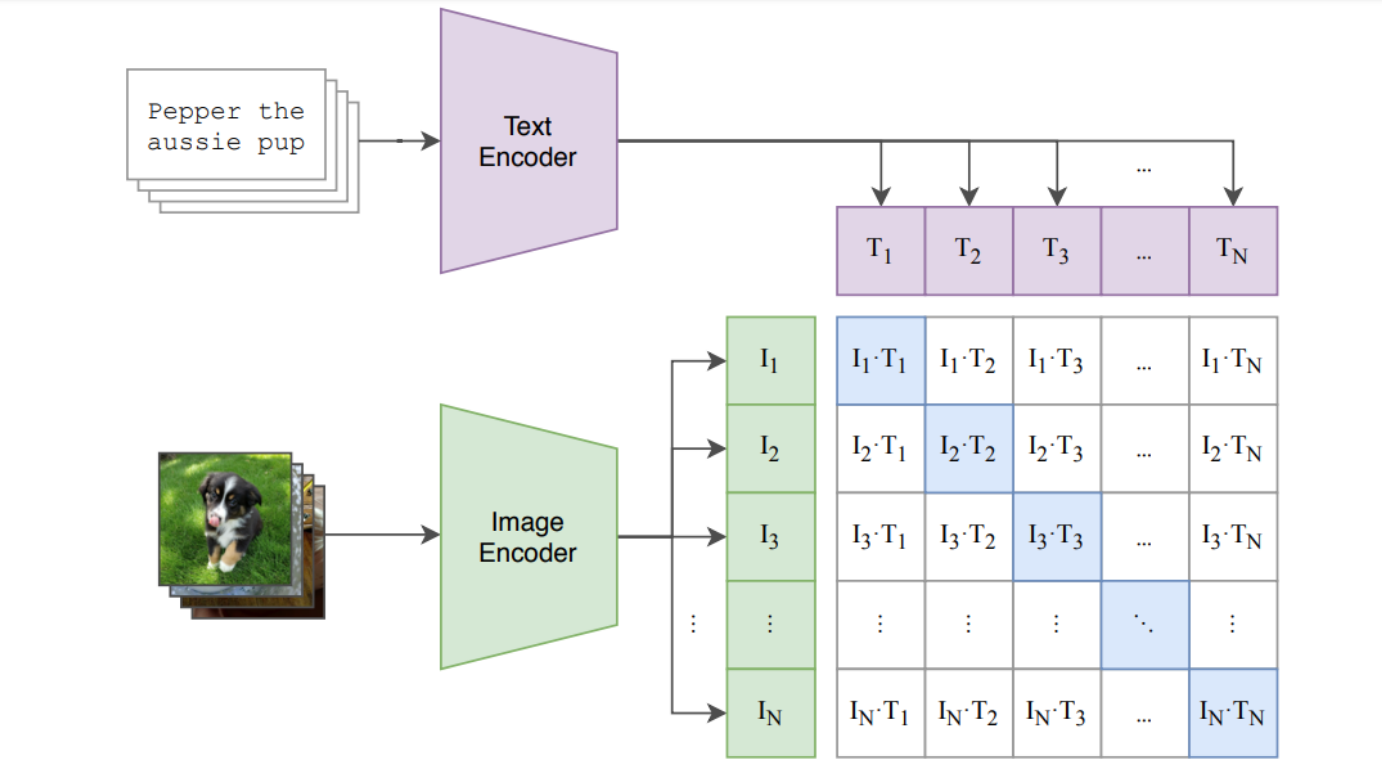
2)视频层面
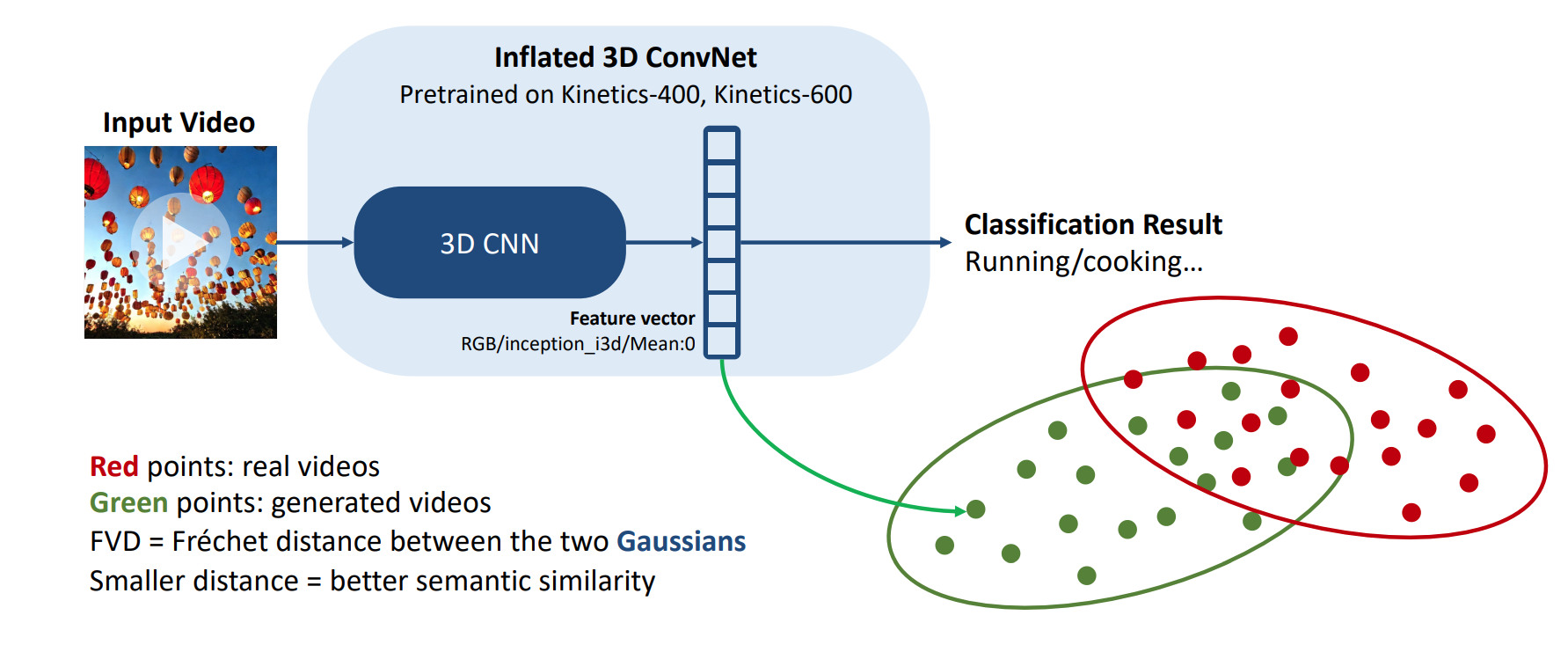
FVD:用3D CNN,计算两个distribution举例也有点不同。

inception score:也是在看distribution,不过他考量的有质量和多样性


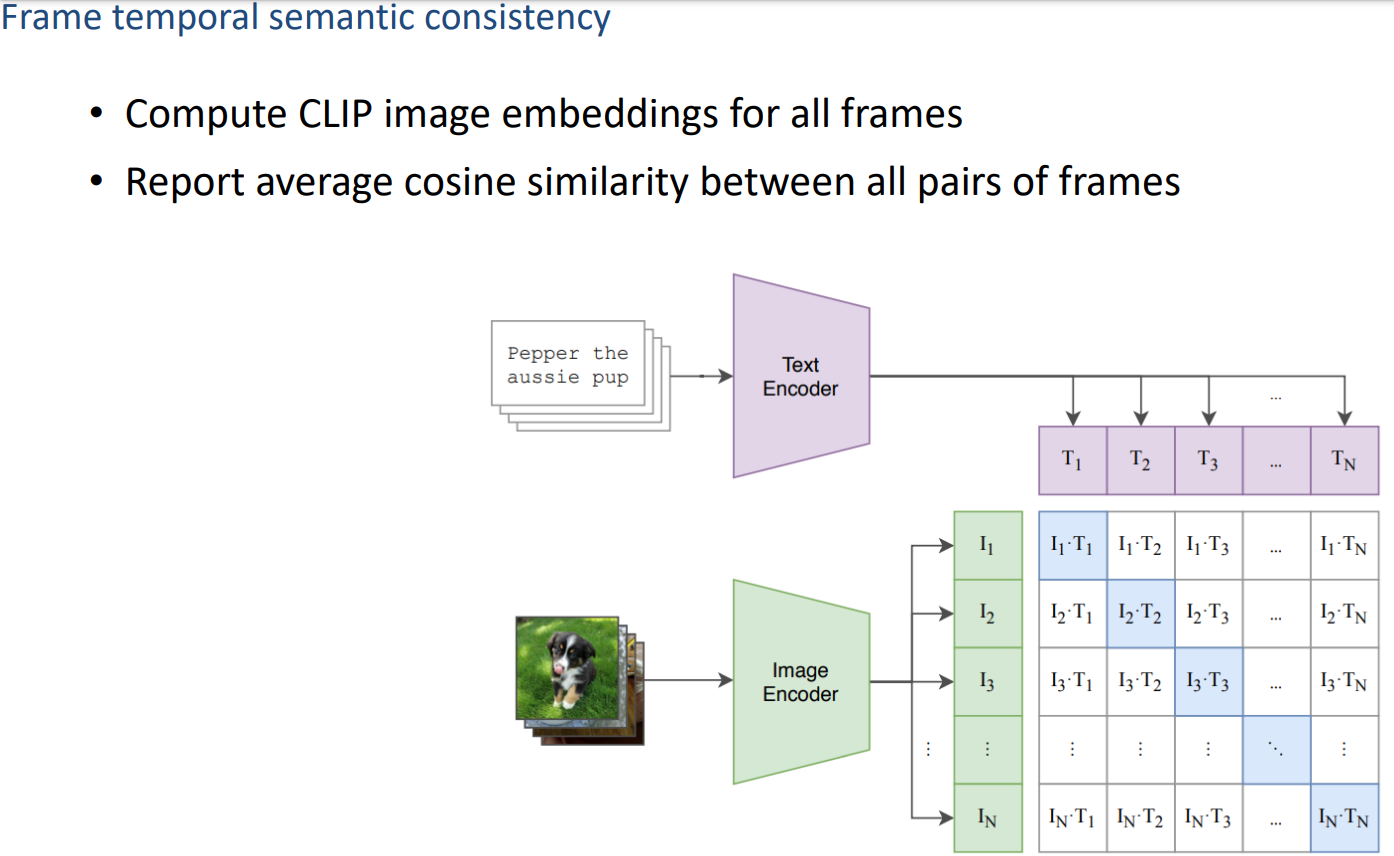
Frame Consistence CLIP scores:计算帧间一致性,将每一帧输入clip得到clip embedding,然后算所有pairs之间的距离有多大

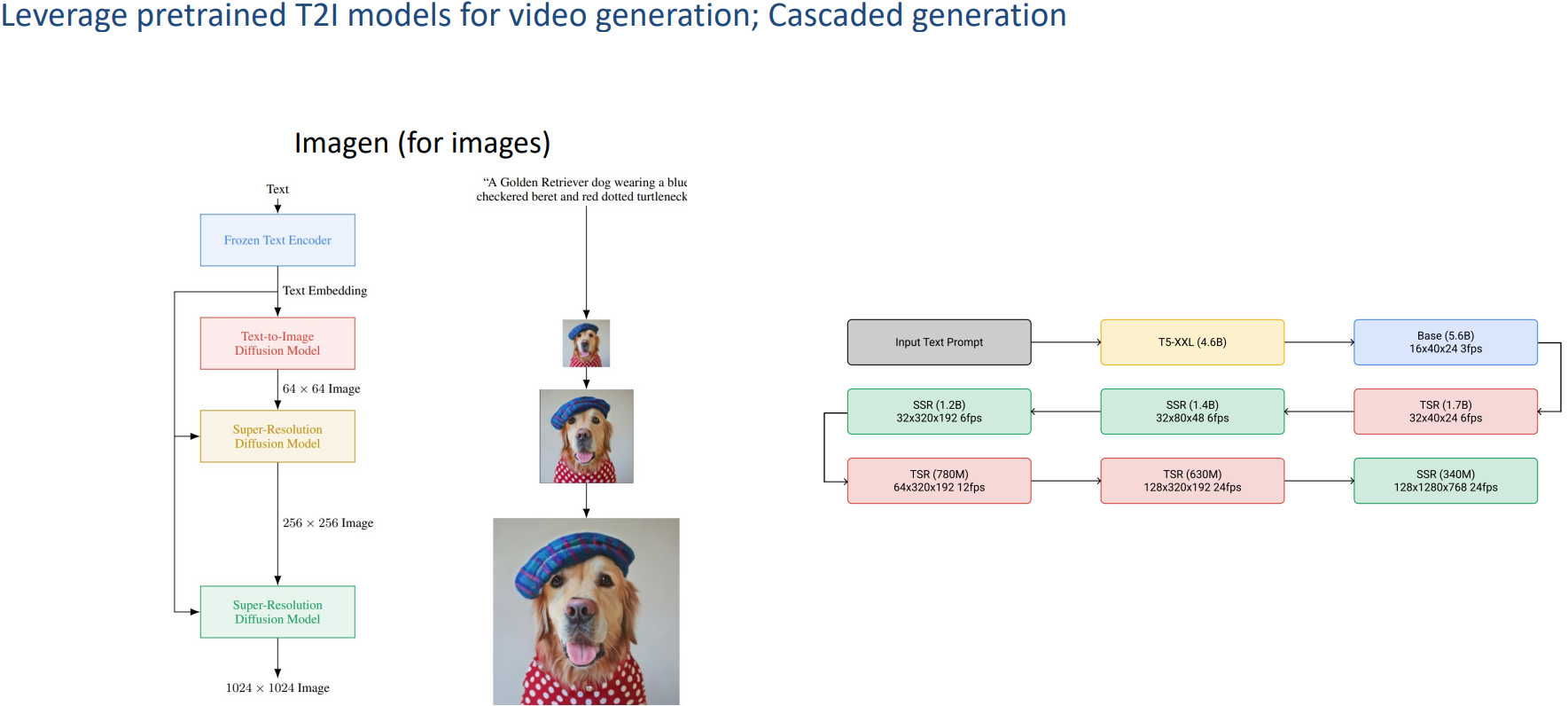
2.1.3 Imagen & Imagen VIdeo
跟make a video一样,也是cascaded generation

2.1.4 Align your Latents
做法也类似,先生成关键帧,然后插帧

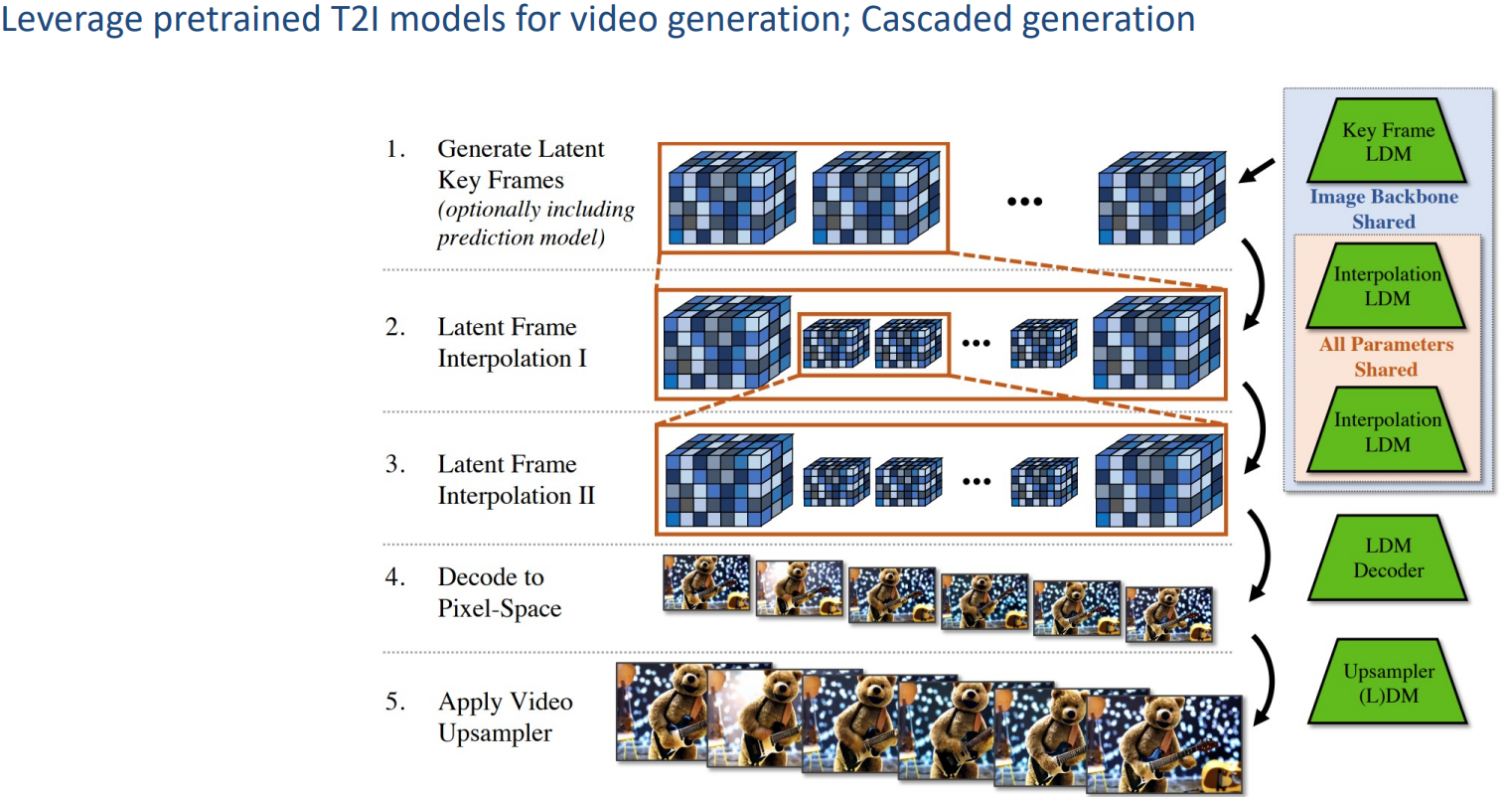
在ldm中插入了temporal convolution和3D attention layers
在decoder中加入了3D convolutional layers
在上采样模块也加入了3D卷积层
2.2 开源工作
2.2.1 ModelScope
ldm结构,把ldm从2D变成3D。

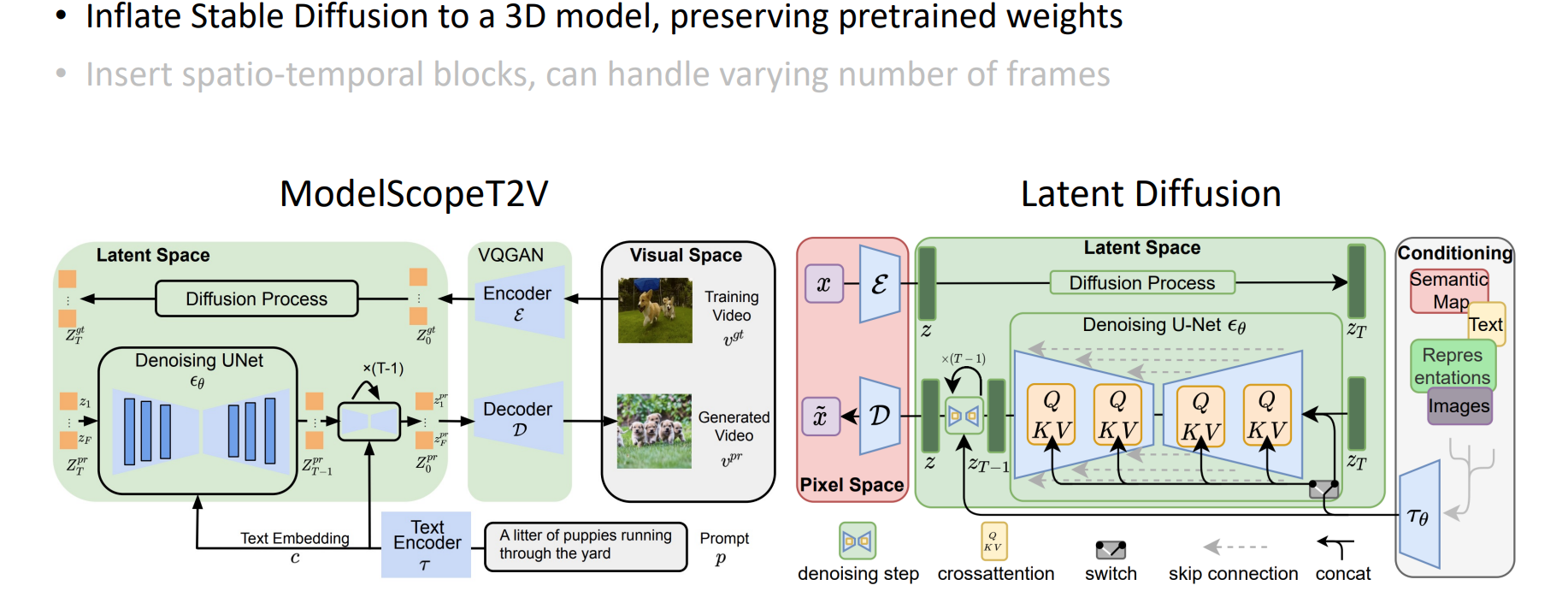
也是使用(2+1)D的方式:spacial conv加temporal conv;spatial attention 加 temporal attention

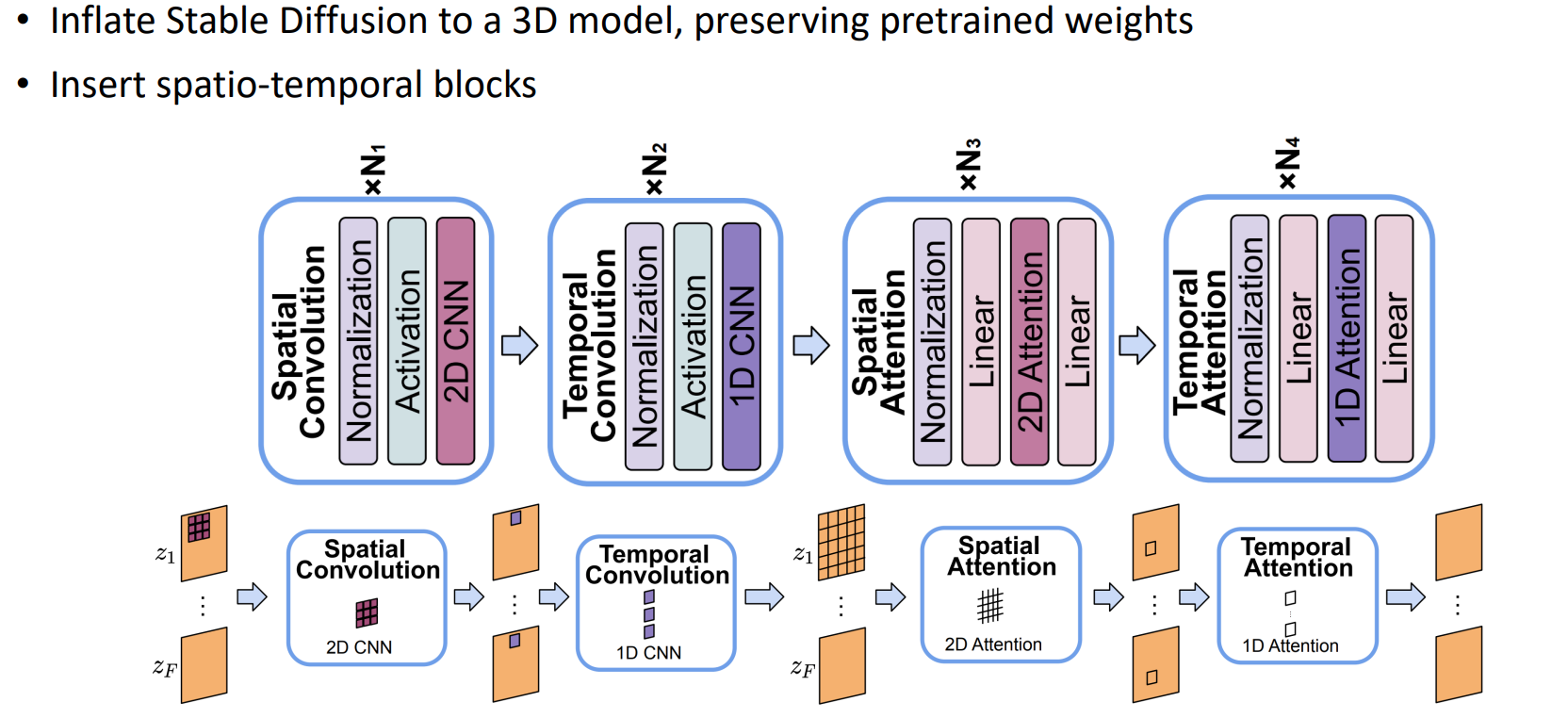
- 值得一提的是,他的temporal convolution的length是可变的,这样可以处理不同数量的帧作为输入。当length=1时就变成了图像生成,训练的时候就可以用图片和视频进行一个join training
2.2.2 Show-1
对视频中的文本信息能更好alignment:发现在pixel space上的方法比latent space上的方法的alignment更好。说明在latent层面的控制还是没有那么精细
在低分辨率生成的时候用pixel space,超分的时候就用latent space
2.2.3 VideoCrafter
2.2.4 LaVie
- 一个更好的数据集
2.2.4 Stable Video Diffusion
把视频里有镜头转换的给切开,把长视频切成小段
进行文本描述
计算美学分数
用光流筛除变化小的scene
训练方法
- 先做image pretraining,然后inflate成3D
- 在数据集上训练
- high quality finetuning
3. 视频编辑
3.1 Tuning-Based
3.1.1 One-Shot Tuned
- 给的视频只有一个,在一个视频上训练
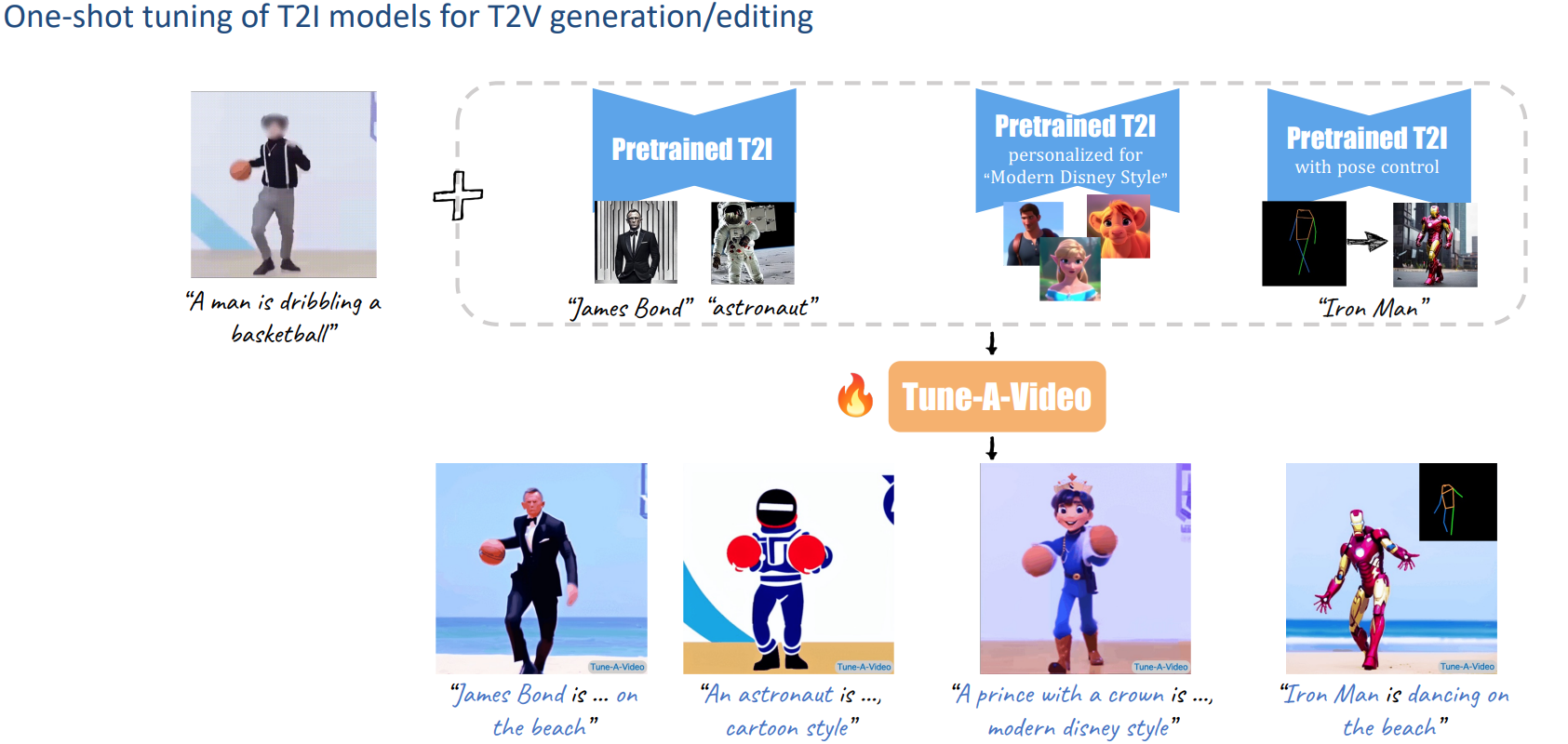
1) Tune-A-Video
给一个文本视频对,更换主体