
4 Bahdanau 注意力
对于机器翻译问题,使用基于两个循环神经网络的编码器‐解码器架构,编码器将长度可变的序列转换为固定形状的上下文变量,然后解码器根据生成的词元和上下文变量按词元生成输出序列词元。然而,即使并非所有输入词元都对解码某个词元都有用,在每个解码步骤中仍使用编码相同的上下文变量。有什么方法能改变上下文变量呢?
Bahdanau等提出了一个没有严格单向对齐限制的可微注意力模型。在预测词元时,如果不是所有输入词元都相关,模型将仅对齐输入序列中与当前预测相关的部分。这是通过将上下文变量视为注意力集中的输出来实现的。
4.1 模型
在序列到序列学习模型的基础上做如下更改:
- 上下文变量$\boldsymbol{c}$在任何解码时间步t′都会被$\boldsymbol{c}_ {t′}$替换。
假设输入序列中有T个词元,解码时间步t′的上下文变量是注意力集中的输出:
$$ \boldsymbol{ c }_ { t ^ ′ } = \sum _ { t = 1 }^ T \alpha \left( {\boldsymbol{ s }_{ t ^ ′ - 1 }, \boldsymbol{ h }_t} \right) \boldsymbol{ h }_t $$
其中,时间步t′ − 1时的解码器隐状态$\boldsymbol{ s }_{ t ^ ′ - 1 }$是查询,编码器隐状态$\boldsymbol{ h }_t$是键,也是值,注意力权重$\alpha$是使用加性注意力评分函数计算的。
Bahdanau注意力的架构:

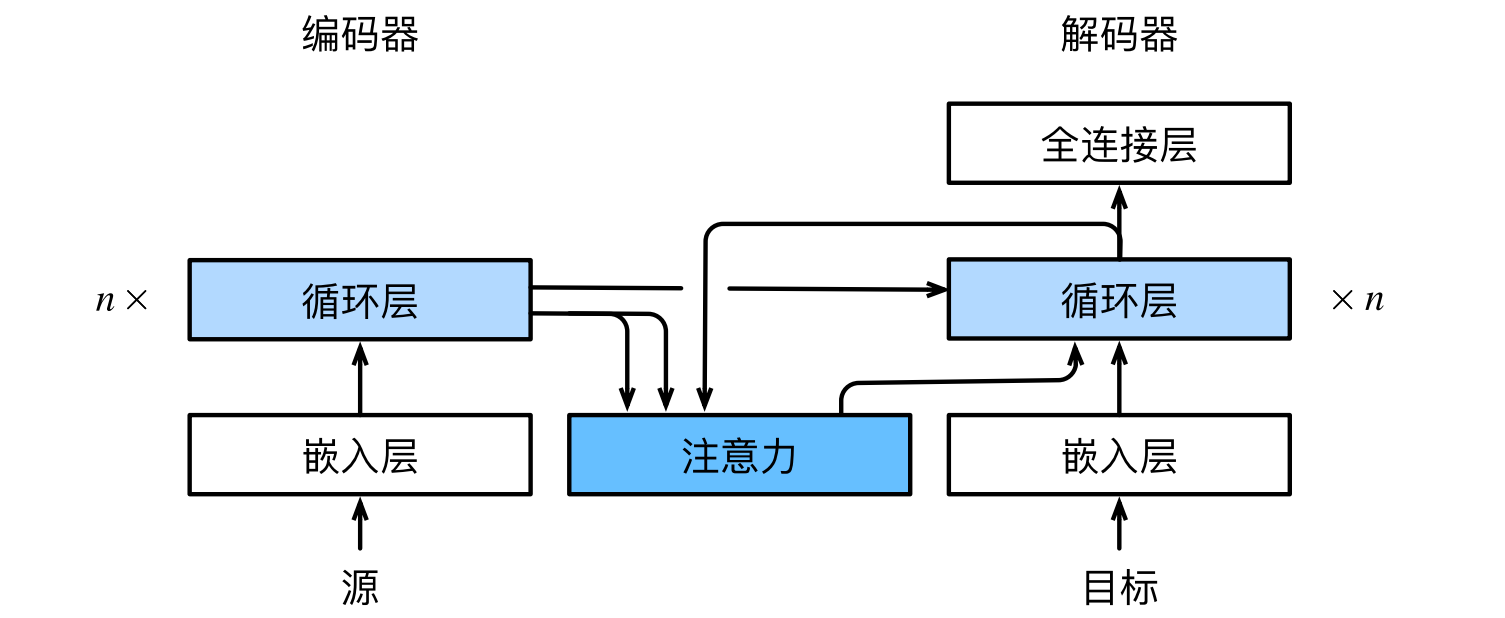
4.2 定义注意力解码器
- 只需重新定义解码器即可。
1 | import torch |
实现带有Bahdanau注意力的循环神经网络解码器,初始化解码器的状态,需要输入:
编码器在所有时间步的最终层隐状态,将作为注意力的键和值;
上一时间步的编码器全层隐状态,将作为初始化解码器的隐状态;
编码器有效长度,避免在注意力汇聚中填充词元。
在每个解码时间步骤中,解码器上一个时间步的最终层隐状态将用作查询。因此,注意力输出和输入嵌入都连结为循环神经网络解码器的输入。
1 | class Seq2SeqAttentionDecoder(AttentionDecoder): |
(torch.Size([4, 7, 10]), 3, torch.Size([4, 7, 16]), 2, torch.Size([4, 16]))
4.3 训练
1 | import os |
loss 0.020, 5397.9 tokens/sec on cpu

- 测试
1 | engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .'] |
go . => va !, bleu 1.000
i lost . => j'ai perdu ., bleu 1.000
he's calm . => il est paresseux ., bleu 0.658
i'm home . => je suis chez moi ., bleu 1.000
- 训练结束后,下面通过可视化注意力权重会发现,每个查询都会在键值对上分配不同的权重,这说明在每个解码步中,输入序列的不同部分被选择性地聚集在注意力池中。
1 | attention_weights = torch.cat([step[0][0] for step in dec_attention_weight_seq], 0).reshape((1, 1, -1, num_steps)) |
