
5 多头注意力
当给定相同的查询、键和值的集合时,我们希望模型可以基于相同的注意力机制学习到不同的行为,然后将不同的行为作为知识组合起来,捕获序列内各种范围的依赖关系(例如,短距离依赖和长距离依赖关系)。因此,允许注意力机制组合使用查询、键和值的不同 子空间表示(representation subspaces)可能是有益的。
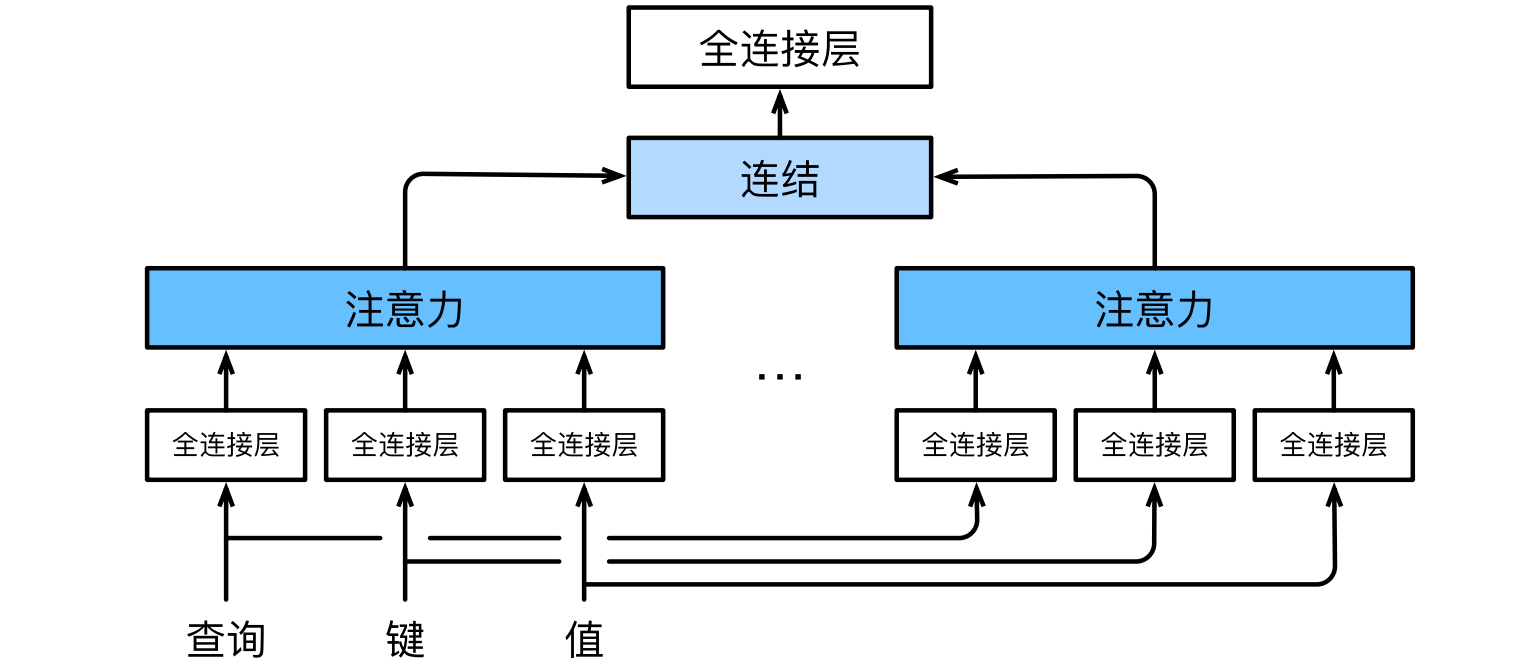
多头注意力(multihead attention):为此,与其只使用单独一个注意力汇聚,我们可以用独立学习得到的h组不同的线性投影来变换查询、键和值。然后,这h组变换后的查询、键和值将并行地送到注意力汇聚中。最后,将这h个注意力汇聚的输出拼接在一起,并且通过另一个可以学习的线性投影进行变换,以产生最终输出。对于h个注意力汇聚输出,每一个注意力汇聚都被称作一个头(head)。

5.1 模型
- 给定查询$ \mathbf{ q } \in \mathbb{ R }^{ d _ { q } } $、键$ \mathbf{ k } \in \mathbb{ R }^{ d _ { k } } $和值$ \mathbf{ v } \in \mathbb{ R }^{ d _ { v } } $,每个注意力头$ \mathbf{ h } _ { i } $($ i = 1,2, \ldots , h $)的计算如下:
$$ \mathbf{ h } _ { i } = f \left( \mathbf{ W } _ { i } ^ { q } \mathbf{ q } , \mathbf{ W } _ { i } ^ { k } \mathbf{ k } , \mathbf{ W } _ { i } ^ { v } \mathbf{ v } \right) $$
- 其中$ \mathbf{ W }$是可学习参数,f是注意力汇聚函数。最后,我们将所有头的输出连接起来,并通过另一个可学习的线性变换$ \mathbf{ W } _ { o } $来得到最终输出:
$$ \mathbf{ W } _ { o } \left[ \mathbf{ h } _ { 1 } ; \mathbf{ h } _ { 2 } ; \ldots ; \mathbf{ h } _ { h } \right] ^ { \top } $$
- 基于这种设计,每个头都可能会关注输入的不同部分,可以表示比简单加权平均值更复杂的函数。
1 | import math |
5.2 实现
- 通常选择缩放点积注意力作为每一个注意力头。为了避免计算代价和参数代价的大幅增长,设定$p _ { q } = p _ { k } = p _ { v } = p _ { o } / h$,其中$p _ { q }$、$p _ { k }$、$p _ { v }$和$p _ { o }$分别是查询、键、值和输出的维度。如果将查询、键和值的线性变换的输出数量设置为$p _ q h = p _ k h = p _ v h = p _ o$,则可以并行计算h个头。
1 | #@save |
- 使用键和值相同的小例子来测试
1 | num_hiddens, num_heads = 100, 5 |
MultiHeadAttention(
(attention): DotProductAttention(
(dropout): Dropout(p=0.5, inplace=False)
)
(W_q): Linear(in_features=100, out_features=100, bias=False)
(W_k): Linear(in_features=100, out_features=100, bias=False)
(W_v): Linear(in_features=100, out_features=100, bias=False)
(W_o): Linear(in_features=100, out_features=100, bias=False)
)
1 | batch_size, num_queries, num_kvpairs, valid_lens = 2, 4, 6, torch.tensor([3, 2]) |
torch.Size([2, 4, 100])